DS 210 - Programming for Data Science - Summer 2026
Welcome to DS 210 - Programming for Data Science in Rust.
This course builds on DS110 (Python for Data Science) by expanding on programming language, systems, and algorithmic concepts introduced in the prior course. The course introduces students to Rust, a compiled and high performance language. It also introduces students to important systems level concepts such as computer architecture, compilers, file systems, and using the command line.
Look at the course’s syllabus and schedule for more details.
Previous Offerings
Course Schedule
This schedule is updated frequently. Please check the readings and exercises before each class.
| Mon | Tue | Wed | Thu | Fri |
|---|---|---|---|---|
| May 18 | May 19 Lecture 1: course overview • why Rust? | May 20 Lecture 2: shell & terminals • Rust & VSCode | May 21 Lecture 3: types & functions Proj 1 out: Guessing game | May 22 |
| May 25 Memorial day Proj 1 due: Guessing game Proj 2 out: Chatbot | May 26 Lecture 4: types & functions • comparing programs Discussion 1: Git basics | May 27 Lecture 5: comparing programs • structs, enums | May 28 Lecture 6: parameter passing • generics & traits Discussion 2: Leetcode! | May 29 |
| Jun 1 Proj 2 due: Chatbot Proj 3 out: Vec | Jun 2 Lecture 7: generics & traits • job & career discussion Discussion 3: Chatbot code review | Jun 3 Lecture 8: memory • pointers | Jun 4 Lecture 9: pointers • LinkedList discussion Discussion 4: No Discussion | Jun 5 |
| Jun 8 Proj 3 due: Vec Proj 4 out: Client-server | Jun 9 Midterm 1 Discussion 5: Vec code review | Jun 10 Lecture 10: ownership & borrowing | Jun 11 Lecture 11: ownership & borrowing Discussion 6: TBD | Jun 12 |
| Jun 15 Proj 4 due: Client-server Proj 5 out: Tic-Tac-Toe | Jun 16 Lecture 12: lifetimes Discussion 7: client-server code review | Jun 17 Lecture 13: managed memory in Python | Jun 18 Lecture 14: data science with Polars Discussion 8: TBD | Jun 19 |
| Jun 22 Proj 5 due: Tic-Tac-Toe | Jun 23 Lecture 15: concurrency and synchronizations Discussion 9: Tic-Tac-Toe code review | Jun 24 Exam study no class | Jun 25 Final Exam | Jun 26 |
Course Deadlines: Assignments and Exams
This is a list of the deadlines for DS 210 - Summer 2026:
-
Mini project 1: Guessing game due May 25
-
Mini project 2: Chatbot
- Code submission via Gradescopedue Jun 1
- Code review Jun 2
-
Mini project 3: Vec
- Code submission via Gradescopedue Jun 8
- Code review Jun 9
-
Midterm exam (in class): Jun 9
- Topics TBD
- Topics TBD
-
Mini project 4: Client-server
- Code submission via Gradescope due Jun 15
- Code review Jun 16
-
Mini project 5: Tic-Tac-Toe
- Code submission via Gradescope due Jun 22
- Code review Jun 23
-
Final exam (in class): Jun 25
- Topics TBD
DS 210 - Programming for Data Science
This course builds on DS110 (Python for Data Science) by expanding on programming language, systems, and algorithmic concepts introduced in the prior course. The course begins by exploring the different types of programming languages and introducing students to important systems level concepts such as computer architecture, compilers, file systems, and using the command line. It introduces Rust, a safe and high performance compiled language, and shows how to use it to implement and understand a number of fundamental data structures, algorithms, and systems concepts.
While DS110 focuses on writing small, standalone Python scripts for data science, DS210 aims to expose students to designing and implementing larger programs and software packages, as well as testing, optimizing, and evaluating these programs.
Prerequisites: CDS 110 or equivalent
Learning Objectives
By the end of this course students will:
- Be familiar with basics of computer organization and how it affects correctness and performance of programs, including the basic computer structure, memory management and safety, and basic concurrency and synchronization.
- Understand how to implement, evaluate, and optimize high performance code.
- Become more comfortable designing and implementing moderately complex software packages.
- Understand how to evaluate and improve the quality of code with respect to readability, maintenance, performance, and modularity.
- Learn basic data structures and algorithmic concepts, e.g., vectors, linked lists, stacks, and hashmaps.
Why are these concepts important?
Jobs/careers: Given the increasing competitiveness of the job market, it is crucial to have a strong technical background in building good quality and performant programs and software to acquire and succeed in data science, data engineering, and software engineering jobs at reputable employers. This course teaches fundamental concepts and practical skills crucial for such employers and jobs. Students who do not master the material in this course will struggle to succeed in such jobs (or even get their careers started).
Technical interviews: Technical interviews almost always include coming up with an effective solution for a data structure or algorithmic problem and implementing it effectively in clean, good quality code. This course helps students practice this skill.
The CDS curriculum: DS 210 plays an important role in the CDS curriculum, with many higher-level courses depending on it as a prerequisite. For many students, it is the only course where they will encounter computer organization and systems concepts that are nonetheless crucial for their success in other practical-oriented upper level courses and practicums.
Student growth and technical background: A data scientist or engineer that does not understand the basics of how a computer works cannot effectively understand why their programs behave the way that they do. The material in this course will help students move past the stage where the data science tools they use are mystery boxes. Instead, students will have a greater understanding of how and why they work, and the behind-the-scenes reasons for why they are designed the way that they are. Thus, helping students use these tools (and learn new ones) more effectively.
Lectures and Discussions
Lectures: Tuesdays, Wednesdays, and Thursdays 1:00pm – 3:30pm, 808 Commonwealth Ave FLR 123
Discussions: Tuesdays and Thursdays 4:00pm – 5:00pm, 590 Commonwealth Ave SCI 115
Consistently attending and participating in both lectures and discussions is expected and constitutes a sizable part of your grade in this course.
Course Content Overview
- Part 1: Why Rust and why should you care? Foundations: command line, git, and Rust basics syntax and features. (Weeks 1-2)
- Part 2: Core Rust concepts. Memory management. Data structures and algorithms. (Weeks 3-4)
- Midterm (~Week 4)
- Part 3: Advanced Rust. Parallelism and concurrency. Data science with Rust. (Weeks 5-6)
- Final exam (Week 6)
For a complete list of modules and topics that will be kept up-to-date as we go through the term, see the lectures schedule and the list of deadlines.
Course Format
Lectures: our lectures will involve extensive hands-on practice. Each class includes:
- Interactive presentations of new concepts, including live coding and visualizations
- Small-group exercises and problem-solving activities
- Discussion and Q&A
Because of this active format, regular attendance and participation is important and counts for a significant portion of your grade (20%).
Discussions: the instructor will work with you on programming exercises and provide project support, and will be used for code reviews.
The discussions count towards the attendance portion of your grade.
Pre-work: we will generally assign short, light readings or small exercises ahead of class to help you prepare for in-class activities, and may include short quizzes (graded to completion) to help us keep track of the class’s progress. We will also periodically ask for feedback and reflections on the course between lectures.
Mini Projects: a key goal of this course is to have you write significant code, both in size and complexity. The only way to master programming is with practice. You can find a tentative schedule of our assignments and their deadlines at this page.
These constitute 50% of your grade:
-
Mini projects: we will have 5 mini projects throughout the course. These are individual assignments that span multiple weeks and are due one week at a time.
-
Code reviews/oral examination: We will also conduct code reviews/oral examination with every student about their solution during the discussion section immediately following their due date. This process will mimic code review practices in industry and offer students feedback about how they improve their solutions and programming skills. They also serve as a check to ensure students only hand in code they have written (and understood) themselves.
Find more details about the mini projects, code reviews, and their policies here.
Exams: One midterm and a cumulative final exam covering the concepts we see in class and in the mini projects. The exams constitute 30% of the final grade.
The course emphasizes learning through practice and receiving feedback on assignments.
Time Commitment
In a typical week, students are expected to attend the three lectures and the one to two discussion sections weekly (~9 hours) and allocate ~0.5-1 hours for class pre-work. This is a coding heavy course, and students will need to allocate 6-8 hours per week on average to work on the mini projects.
The best way to practice for the exams is by doing the mini projects and engaging in the lecture pre-work and in-class activities. However, we will adjust the assigned workload during the week of the midterm and final to allow students some time to review the lecture notes and material, if they so wish.
In total, we expect students to allocate 16-20 hours per week to DS 210 between attending lectures, discussion, and projects.
This is a programming heavy course that pushes students to practice and improve their programming skills. We believe this is crucial to students’ careers, growth, and job prospects. In return, the teaching staff commits to dedicating themselves to helping the students in and outside of class, and providing them with feedback, resources, and guidance to ensure they succeed.
We are on your side as you battle programming, computers, and the Rust compiler.
Course Staff
Instructor: Kinan Dak Albab
Email: babman@bu.edu
Office hours: Thursdays 11-12 @ CDS 1336
If you want to meet but cannot make office hours, send a private note on Piazza with at least 2 suggestions for times that you are available, and we will find a time to meet.
Course Websites and Material
- Syllabus (this document)
- Interactive lecture notes
- Schedule page
- Homework, Mini project, and exam deadlines
Piazza
- Announcements and additional information
- Questions and discussions
- Code from lectures and discussion sections
- In-class coding exercises and their solutions
- Project stencils
Gradescope
- Homework and in class activities submission
- Gradebook
- Programming exercises and challenges
- The standard for practicing for technical interviews!
Other Resources
The Rust Language Book
by Steve Klabnik, Carol Nichols, and Chris Krycho, with contributions from the Rust Community
This is a great resource that goes over the various Rust languages features in detail. It starts with the basics (variables, types, and loops) and ends with more advanced features (concurrency, unsafe).
Brown University Experimental Rust Book
This is a fork of the official Rust Language Book with integrated short quizzes and language visualizations.
- Website: https://rust-book.cs.brown.edu/index.html
- Repo: https://github.com/cognitive-engineering-lab/rust-book
Grading, Assignments, and Exams
Grade breakdown
Your grade will be determined as:
- 50% mini projects (5 projects)
- 10% midterm
- 20% final exam
- 20% attendance and participation: includes lectures, discussion sections, pre-work, surveys, and in-class activities
We will use the standard map from numeric grades to letter grades (>=93 is A, >=90 is A-, etc). For the midterm and final, we may add a fixed number of “free” points to everyone uniformly to effectively curve the exam at our discretion - this will never result in a lower grade for anyone.
We will use Gradescope to track grades over the course of the semester, which you can verify at any time and use to compute your current grade in the course for yourself.
Some mini projects will offer opportunities for extra credit which provide a supplement on top of the grades from the above (i.e., allow students to get more than 100% or make up for lost work).
Assignments Grading and Policies
Mini projects
Our 5 mini projects are graded equally as follows:
- 60% correctness and performance: whether your code passes our tests within the allocated time.
- 40% code reviews / oral examination: include code quality, collaboration, and analysis/reflection.
You will get partial credit for solutions that do not pass all the tests or that take longer than the allocated time. This partial credit is proportional to how far your solution is from one that meets our tests and performance. You may receive some partial credit for code that does not compile or otherwise fail to pass any of the tests, provided that it demonstrates some conceptual understanding of the material.
Code reviews
We will have 4 code reviews in total, one for each of mini projects 2–5. We will hold the code reviews during the discussion sections immediately following the mini project deadline. We will review late submissions at their current state, provided they are sufficiently near completion. If you have no code or progress to show during code review, you will receive a 0 on that mini project.
Code review format: Each student will have their own code review during the discussion section (roughly 15 minutes long). The reviewer will be the instructor.
Code review contents: The code reviews will provide you with feedback about the design of your code and any potential issues. The review will include verbal questions and will go over your code and commit history.
We will ask you to explain certain code blocks, justify your design or approach, or compare it with other hypothetical approaches. The review will also contain reflection questions that ask you to draw conclusions or highlight lessons you learned from working on the assignment.
Absences: You must be present for your code review. You may request an alternative time provided reasonable justification, and we will work to find a suitable arrangement, e.g., in office hours.
Please give at least 2 days notice before requesting rescheduling. Missing code review without a documented excuse or prior notice may result in 0 for that mini project.
Online Resources and AI Use
Wholesale use of AI on assignments is forbidden. We define wholesale to mean asking AI to generate chunks of code, such as entire functions, structs, or complex multi-line code blocks.
We encourage you not to mindlessly use AI to help with your assignment. This can lead to over-reliance on AI and defeat the purpose of the assignment: for you to practice your coding skills. Limited use of AI, e.g., to find particular API calls, is allowed, provided you are able to explain your code, design choices, and reason about the decisions you made during code review. The same applies to other resources, such as Stack Overflow. You will need to document such code with a comment and provide a link to the online resource or relevant prompts you used.
AI Use Document: You will be required to submit a short document with each assignment describing how you used AI, if at all. We will confirm your understanding of the code, and whether any AI use was within acceptable parameters in the code reviews.
Over reliance on AI: If you are unable to adequately explain your code or answer questions about it in code review due to over-reliance on AI consistent with your AI use document, you may lose a significant portion of your code review portion of the grade.
Academic dishonesty: If you fail to honestly report your use of AI or online resources and we confirm this via our code review, you will receive a 0 on that mini project, and your final grade in the course will be capped at a B. A repeat violation will result in an automatic F. We may refer egregious cases to the appropriate CDS and BU committees.
Due date and late submission
Our mini projects are generally due on Mondays, 11:55pm. Students have the option to submit up to two days late for a maximum of 80% of the assignment’s grade.
Attendance
We will track attendance in lectures via in class polls. These polls track the location of the students to ensure they are physically at class.
We understand that unexpected circumstances can happen: students may miss up to 2 lectures and 1 discussion section without having to provide an excuse.
We will accommodate documented absences within reason and inline with BU’s policies and guidelines, but may ask for official documentation.
Course Policies
Exams
The final will be in class on June 25. The midterm will be in class during normal lecture time.
If you have a valid conflict with a test date, you must tell us as soon as you are aware, and with a minimum of one week notice (unless there are extenuating circumstances) so we can arrange a make-up test.
If you need accommodations for exams, schedule them with the Testing Center as soon as exam dates are firm. See below for more about accommodations.
Deadlines and late work
Assignments will be due on the date specified in Gradescope.
If your work is up to 48-hours late, you can still qualify for up to 80% credit for the assignment. After 48 hours, late work will not be accepted unless you have made prior arrangements due to extraordinary circumstances.
Collaboration
Mini projects are individual work.
You are free to discuss problems and approaches with other students, but must do your own coding. If a significant portion of your solution is derived from someone else’s work (your classmate, a website, a book, etc), you must cite that source in your writeup.
You must also understand your solution well enough to be able to explain it during code review. You will not be penalized for using outside sources as long as you cite them appropriately and meet the code review expectations.
Academic honesty
You must adhere to BU’s Academic Conduct Code at all times. Please be sure to read it here.
In particular: cheating on an exam, passing off another student’s work as your own, or plagiarism of writing or code are grounds for a grade reduction in the course and referral to BU’s Academic Conduct Committee.
If you have any questions about the policy, please send us a private Piazza note immediately, before taking an action that might be a violation.
AI use policy
You are allowed to use GenAI (e.g., ChatGPT, GitHub Copilot, etc) to help you understand concepts or lecture notes.
For mini projects, you are only allowed to use AI in limited, piece-meal fashion, e.g., to search for a particular API, or explain a very specific error you are encountering. You should understand that this may help or significantly impede your learning depending on how you use it.
If you use GenAI for an assignment, you must cite what you used and how you used it (for brainstorming, autocomplete, generating comments, fixing specific bugs, etc.). You must understand the solution well enough to explain it during code review.
If you fail to honestly report your use of GenAI for an assignment and we confirm this via code review, you will receive a 0 on that assignment and your final grade in the course will be capped at a B. A repeat violation will result in an automatic F. We may refer egregious cases to the appropriate CDS and BU committees.
Your instructor is happy to help you write and debug your own code during office hours, but will not help you understand or debug code generated by AI.
For more information see the CDS policy on GenAI.
Attendance and participation
Since a large component of your learning will come from in-class activities and discussions, attendance and participation are essential and account for 20% of your grade.
Attendance will be taken in lecture through polls which will open at various points during the lecture. If you miss such a poll (e.g., due to being significantly late to class), that will count as an absence. The polls use a custom made website that confirms your location. Attempting to submit such a poll from a different location (e.g., your home) will be detected and may constitute an instance of academic dishonesty/cheating.
Understanding that illness and conflicts arise, students may miss up to 2 lectures and 1 discussion section without having to provide an excuse.
In most lectures, there will be time for small-group exercises, either on paper, GitHub, or Gradescope. To receive participation credit on these occasions, you must identify yourself on paper or in the repo/Gradescope submission. These submissions will not be graded for accuracy, just for good-faith effort.
Occasionally, we may ask for volunteers, or may cold call students randomly to answer questions or present problems during class. You will be credited for participation/in-class activities for such contributions.
Absences
This course follows BU’s policy on religious observance. Otherwise, it is generally expected that students attend lectures and discussion sections. If you cannot attend classes for a while, please let us know as soon as possible. If you miss a lecture, please review the lecture notes on this website before the next class.
Accommodations
If you need accommodations, let us know as soon as possible. You have the right to have your needs met, and the sooner you let us know, the sooner we can make arrangements to support you.
This course follows all BU policies regarding accommodations for students with documented disabilities. If you are a student with a disability or believe you might have a disability that requires accommodations, please contact the Office for Disability Services (ODS) at (617) 353-3658 or access@bu.edu to coordinate accommodation requests.
If you require accommodations for exams, please schedule that at the BU testing center as soon as the exam date is set.
Re-grading
You have the right to request a re-grade of any assignment or test. All regrade requests must be submitted using the Gradescope interface. If you request a re-grade for a portion of an assignment, then we may review the entire assignment, not just the part in question. This may potentially result in a lower grade.
DS210 Course Overview
Lecture 1: Tuesday, May 19, 2026.
This lecture introduces DS 210: Programming for Data Science, covering course logistics, academic policies, grading structure, and foundational concepts needed for the course.
Overview
This course builds on DS110 (Python for Data Science). That, or an equivalent is a prerequisite.
We will spend the bulk of the course learning Rust, a modern, high-performance and more secure programming language. While running and using Rust, we will cover important foundational concepts and tools for data scientists and programmers:
- Tools
- Shell commands
- Git version control
- Computer architecture and systems
- Overview of CPU architectures and instruction sets
- Memory layouts and memory management
- Basic parallelism and synchronization
- Algorithmic foundations
- Basics of runtime analysis and big O notation
- Basic data structures (vectors, linked-lists, hashmaps) and their uses
Why is it important for data science students to learn these concepts?
- It is important to have a strong technical background in effective programming for your future careers. This includes understanding how the computer works, and how that affects the performance and correctness of your programs.
- You need knowledge of data structures and algorithms and to be able to put that knowledge into clean, concise code to succeed at technical interviews.
- Many upper courses in the CDS curriculum require a good background in the topics we will learn in 210.
- This course and the hands-on programming practice are an opportunity for technical and professional growth.
Consult the syllabus for detailed information about the course objectives.
Summer Format
This is a condensed summer offering of DS 210. A few things to keep in mind:
- Pace: the course covers the same material as the semester-long offering in 6 weeks. Lectures are 2.5 hours long (3 per week) and discussions are 1 hour (2 per week). Expect a significantly higher weekly time commitment than a typical course.
- Individual projects: all 5 mini projects are individual work — no groups.
- One midterm: there is one midterm exam (week 4) and a final exam (week 6).
Question: What have you heard about the course? Is it easy? Hard? What are you most looking forward to or most nervous about?
Course Timeline and Milestones
The course is roughly split into these units:
- Part 1: Foundations (command line, git) & Rust Basics (Weeks 1-2)
- Part 2: Core Rust Concepts. Memory management. Data structures and algorithms. (Weeks 3-4)
- Midterm (~Week 4)
- Part 3: Advanced Rust. Parallelism and concurrency. Data science with Rust. (Weeks 5-6)
- Final exam (Week 6)
Mini projects are generally due on Mondays. Check the deadlines page.
Course Format
Lectures with hands-on exercises and active discussion. Attendance is required.
Discussions will review and reinforce lecture material and provide further opportunities for hands-on practice. We will allocate specific discussion sections for code reviews. Attendance is also required.
Pre-work will be assigned before most lectures to prepare you for in-class activities. These are typically short readings followed by a short quiz.
Mini projects are the key to learning the material in this course and to getting a good grade. There are 5 individual mini projects proceeding at a weekly pace.
Exams: 1 midterm and a cumulative final exam covering the concepts we learn in class.
Full details here.
Course Websites
You have been added to Piazza, we will also add you to Gradescope.
-
Piazza:
- Announcements and additional information
- Questions and discussions
-
Gradescope:
- Mini project submissions
- Gradebook
Grading and Policies
Grade distribution:
- 50% mini projects (5 projects)
- 10% midterm
- 20% final exam
- 20% attendance and participation (lectures, discussions, pre-work, in-class activities)
Important course and grading policies:
- code reviews for mini projects
- late submissions
- We encourage you to not use AI during your mini projects work, but if you must, you need to follow our
AI use policy
- You must report your use of AI and online resources along your submission
- If we judge that you over-relied on AI given what you reported (e.g., during code reviews), we will deduct grades appropriately
- If we judge that you did not honestly report AI use, you will receive a 0 for the mini project and your grade will be capped at a B. A repeat violation is an automatic F.
- Other course policies: exams, collaboration, absences, accommodations.
We are not trying to be strict around AI-use for no reason. Instead, we believe this is necessary to ensure you get proper programming practice and truly learn this material. Given our policies and justification, do you feel like this policy is reasonable? Do you agree with it? Do you feel it is too restrictive?
Why Rust?
Lecture 1: Tuesday, May 19, 2026.
Code examples
A common question we get from students is why did we choose to use Rust for this course instead of a different language? Why not continue with Python since it was used in DS 110?
It is important for us to explain our rationale in some detail, and demonstrate to you the motivation behind these decisions. Throughout the course, you will struggle with some Rust-specific concepts and idiosyncrasies. We want you to understand that there is a reason you have to put up with (and overcome) all the hurdles of learning a new language and in dealing with the Rust syntax, compiler, and borrow checker.
Why learn a new programming language? Why not continue to use Python?
Learning a second programming language builds CS fundamentals and teaches you to acquire new languages throughout your career.
Importantly, it also helps you distinguish what is an inherent property of how computers or algorithms work, and what is simply an incidental design decision, implementation choice, or a convention from a particular programming language ( and why that language made these choices, which often has deep and interesting justifications).
Example 1: What do we mean by an incidental choice?
Consider the following Python code:
print('hello world!')
We are all familiar with what this code does. However, nothing in it is particularly insightful about the essence of computers
or programming or even necessary given how they work. The fact that printing uses the word print is incidental. Other languages use
a different word for it, e.g., println in Rust, cout in C++, or console.log in Javascript.
In Python 3, printing is a function call, as evident by the parenthesis following print above. But it does not have to be this way:
in Rust, it is a macro (as we will see later), and even in Python 2, you could print using print "hello world".
Finally, Python does not really distinguish between " and ', but other languages, like Rust, do!
Example 2: Diving deeper into good and bad design choices
Consider the following Python code:
x = 2
y = '3'
print(x + y)
What is the output of running this code?
The above code produces a runtime error when run:
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Is this the result of a fundamental aspect of how computers work? Not really. In fact, in other languages, similar code will have different behaviors.
In Javascript and Java, 2 + "3" results in “23”! These languages implicitly upgrade 2 to a string. Interestingly, in Javascript, 2 * "3" gives 6, but not in Java!
If you were responsible for designing your own language. What alternative behaviors would you consider for
2 + '3'?
Some of your answers:
- “23”
- 5
- an error only if the string is truly a string, e.g.,
2 + 'hello', and 5 otherwise.
Some other answers we think would not be good:
- 0 or the empty string
- 5 for
2 + '3'but2hellofor2 + 'hello' - The number 23 (as a number, not a string).
It seems like there is a range of answers that are acceptable/somewhat reasonable, and a range of clearly unreasonable answers. What are the criteria that distinguish the two?
- Whether the choice reflects our natural/intuitive expectations as humans/programmers
- Whether the choice is confusing or has many corner cases
- Whether the choice results in silent failures if the program is executed that are hard to debug
Example 3: What are the tradeoffs at play when looking at competing choices
Consider the following Python code:
if 10 > 0:
x = 5
print(f"hello world {x}")
The below Rust code is equivalent:
fn main() { if 10 > 0 { let x = 5; println!("hello world {x}"); } }
Running both pieces of code (e.g., using the Rust playground) reveals
that they both produce identical output: hello world 5.
What are the most visible differences between the two code snippets
- The Rust code is contained within a function whose name is
main. - Python uses
:and indentation, Rust uses{and}. - Python delimits statement with new lines, Rust uses
;. - Variable declaration looks different, python does not distinguish from initial variable declaration and changing it in the future, Rust does by requiring initial declaration use
let.
We will understand what (1) and (4) mean later in the course. Let’s focus on (2) and (3).
The following code is valid in Rust, however the same style in Python would not work: (a) the code is not indented properly, and (b) multiple statements share the same line.
fn main() { if 10 > 0 { let x = 5; println!("hello world {x}"); } }
Which do you prefer?
- Some of you prefer Python’s style. Reasons include:
- being easier to read
- looking nicer and shorter (no
mainfunction) - you are already more familiar with Python: that code feels more natural
- Others prefer Rust:
- no issues with indentation (e.g., mixing spaces and tabs): these are a major headache when writing Python code
So, both approaches have nice things (and not so nice things). What dimensions are at odds here?
How nice the code looks and how easy it is to read vs how easy it is to write! E.g., indented code looks nicer
and shorter than code with { and }, but dealing with spaces and tabs is a headache while writing the code.
We call the first readability and the second writability. Sometimes these are subjective, sometimes they are less so.
We will see many more examples later.
Example 4: Mutability — can variables change?
Consider the following Python code:
x = 5
print(x)
x += 1
print(x)
What is the output? Is there anything surprising about this code?
The output is:
5
6
Nothing surprising from a Python perspective: we assigned x to 5, then incremented it. Python lets you reassign any variable at any time without restriction.
Now, consider the equivalent Rust code:
fn main() { let x = 5; println!("{x}"); x += 1; println!("{x}"); }
What do you think happens when we try to compile this?
Unlike Python, this does not compile. Rust gives us the following error:
error[E0384]: cannot assign twice to immutable variable `x`
|
| let x = 5;
| -
| |
| first assignment to `x`
| x += 1;
| ^^^^^^ cannot assign twice to immutable variable
By default, all variables in Rust are immutable1 — once assigned, they cannot be changed.
Definition:
im·mu·ta·ble
adjective
unchanging over time or unable to be changed
If we want a variable to be reassignable, we must explicitly opt into mutability using the mut keyword:
fn main() { let mut x = 5; println!("{x}"); x += 1; println!("{x}"); }
This compiles and produces the same output as the Python version.
Why would Rust make variables immutable by default? What is the tradeoff compared to Python?
One of the most common sources of bugs in large programs is a variable being changed somewhere unexpected — by a far-away part of the code, or inside a function you called. In Python, nothing stops this from happening silently.
By requiring you to explicitly mark variables as mut, Rust forces you to be deliberate about what can change. If something changes that you did not intend to change, the compiler will catch it.
The tradeoff: Python is more convenient (you never have to think about this), while Rust is safer and more explicit — at the cost of having to write mut when you need it.
What about a language where mutability is the default and you explicitly mark variables as immutable — the opposite of Rust?
This is actually how some languages work (e.g., using a const or final keyword). It provides the same safety guarantee in principle: you can still signal that a variable should not change. However, the default matters a lot in practice. Most variables in well-written programs are never reassigned after their initial value — they are used as named constants or intermediate results. If mutability is the default, programmers have to actively remember to mark every such variable, and forgetting means silently missing out on the safety guarantee. Rust’s choice to make immutability the default means safety is what you get for free, and you only pay the cost (writing mut) when you genuinely need to change something.
Okay, you convinced us that we should learn a second language. Why Rust specifically?
Rust is a compiled language! It is very fast! It is also very different from Python!
What about other compiled and fast languages, like C++?
Compared to C++, Rust offers two important advantages:
Memory safety: Rust lets you see how data structures work in memory and manage your own memory, while reducing the risk of making various memory-related mistakes (e.g., a lot of the C/C++ headaches)
Strong type system: Rust has a strong type system that helps programmers writing Rust code ensure their programs are correct, memory safe, and type safe. We will understand what that means in the future.
In other words, the Rust compiler gives you errors and hints about your code to help you write code correctly, rather than allow you to write code any way you want, and then have to deal with fixing it when you encounter various errors during runtime.
Furthermore, Rust is experiencing growing adoption in industry and academia alike. This spans many fields, from low-level systems programming (e.g. the Linux kernel), software engineering, to data science and scientific computing!
We will investigate these notions in more depth later.
Rust, The Rust Compiler, and Speed
A big reason for why we want to teach you a compiled language, and specifically Rust, is that it is fast. But how fast is Rust (or compiled languages in general) you may ask.
Consider our very first, proper code example.
In this example, you can see two equivalent pieces of code in Rust and Python. The code first creates a list with many numbers (10 million numbers!), then sums all these numbers using a simple loop.
In the code, we measure the elapsed time between the start and end of that loop. In other words, the time that it takes to sum up the 10 million numbers.
First, we run the python code using cd src && python3 example.py. On my machine, the sum takes ~310ms. This is impressive! Imagine how long it would take
you, a human, to add up 10 million numbers.
Next, we run the rust code using cargo run. On my machine, the result takes 30ms. That is a 10x improvement! In other words,
if you were a company in the business of adding numbers (which is more or less what all the big AI companies do), you just cut down
your compute costs by a factor of 10! Big savings!
But wait. It gets better. We can ask Rust (specifically, the Rust compiler) to automatically optimize our code as much as it can using
cargo run --release. Now, the result takes ~1.5ms an impressive 200x speedup, or alternatively, a 200x reduction in compute costs.
BIG SAVINGS.
REALLY REALLY BIG SAVINGS.

What is a compiler? Why is it fast?
The content of the python file example.py is human-readable (some may disagree). It contains things like comments, variables with intelligible names, among other things.
Importantly, it is not written in a computer’s native tongue: the ol’ zeros and ones.
Notice how we ran the python code. We first type in the python3 command, then give it the name of the file we want to run. The python3 command is a translator: it is
responsible for reading out the file one line at a time, and translating it to the computer as it goes through it, telling the computer what to do.
This is a lot like when you watch a live TV speech in a foreign language: the TV station super imposes the voice of a live interpreter, that translates every sentence from the speaker’s
language to English, allowing us to understand what the speaker says, but, often at a noticeable delay.
The python3 command does exactly that (which is why it is in fact called the Python interpreter), except the delay it introduces is even more significant (in relative terms), thus causing slower execution of code.
Rust instead does not have an interpreter, it is a compiled language. We can see how that operates using the following commands in our example code above:
# This compiles (or builds) but does not run the code
cargo build
# This takes us to the folder where the compiler produces the compiled code
cd target/debug/
# The compiled code is in a file called example
# This runs it
./example
You can see that our Rust code, once compiled, can be run directly, without any other commands: there are no interpreters!
Furthermore, we can print the contents of the compiled file. Note that it is not human-readable at all! This is all in zeros and ones, in the computer’s native tongue.
# This takes us to the folder where the compiler produces the compiled code
cd target/debug/
# print the content of the compiled file
cat ./example
Finally, cargo run is simply a helpful shortcut that first compiles the code, then runs the compiled code.
Rust lets us get more visibility into how the computer works
Look at our second code example:
rows.rs and columns.rs are almost identical. Both create a large matrix of dimensions 10,000x10,000 (100 million elements) and sum all its elements
while timing the duration required for the sum.
The one difference is that rows.rs goes through the matrix one row at a time, starting from the first row. While the columns.rs goes one column at a time,
starting from the left most column.
Both add the same number of elements (100 million), so it stands to reason that they will take a similar amount of time. Let us see if that is the case:
cargo run --bin rows # runs rows.rs
cargo run --bin columns # runs columns.rs
On my machine, there is a noticeable difference: columns.rs is roughly 3x slower than rows.rs! Why?
It turns out this difference is entirely related to how the computer works, and not the algorithmic nature of either code (which is similar). Specifically, it has to do with how the CPU in a computer fetches the numbers from its memory (i.e., RAM), and how the numbers inside the matrix are placed in that memory. We will look at the details of computer memory and its structure later.
Key takeaway: the important lesson is that we need to understand how the computer works to inform us in how to write the most efficient formulation of our desired program.
-
Change and mutability is a constant in our lives. Unlike in Rust, almost nothing is immutable in reality. If you want to intuitively feel what it means to be immutable or unchanged, listen to this album. ↩
Shell & Terminals
Lecture 2: Wednesday, May 20, 2026.
Script examples
Every movie with hackers

The matrix had a legit terminal though

What is the terminal?
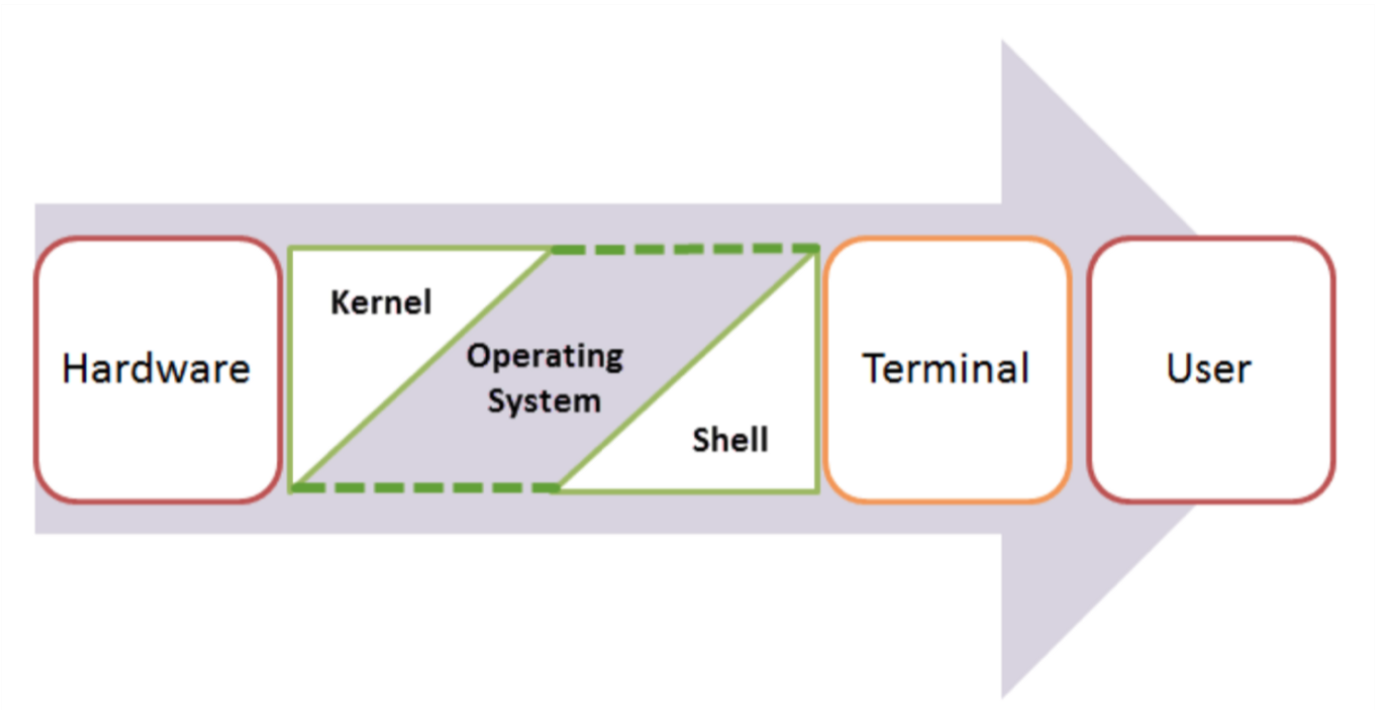
Shell, Terminal, Console, Command line… too many words?
- The command line is the interface where you type commands to interact with your computer.
- The command prompt is the character(s) before your cursor that signals you can type and can be configured with other reminders.
- The terminal or console is the program that opens a window and lets you interact with the shell.
- The shell is the command line interpreter that processes your commands. (You might also encounter “a command line” in text-based games)
Terminals are more like applications and shells are more like languages.
Some famous Terminals:
- Terminal (macOS)
- iTerm2 (macOS)
- GNOME Terminal (Linux)
- Konsole (Linux)
- Command Prompt (Windows)
- PowerShell (Windows)
- Git Bash (Windows)
Famous Shell interpreters:
- Bash (Bourne Again SHell) - most common on Linux and macOS (Kinan’s favorite)
- Zsh (Z Shell) - default on modern macOS
- Fish (Friendly Interactive SHell) - user-friendly alternative
- Tcsh (TENEX C Shell) - popular on some Unix systems
- PowerShell - advanced shell for Windows
We often use all these words interchangeably in speech:
- “Open your terminal”
- “Type this command in the shell”
- “Run this in the command line”
- “Execute this in your console”
What is this all good for?
Lightning fast navigation and action
# Quick file operations
ls *.rs # Find all Rust files
grep "TODO" src/*.rs # Search for TODO comments across files
wc -l data/*.csv # Count lines in all CSV files
Question: How would you do this manually?
It’s how we’re going to build and manage our Rust projects
# Start your day
git pull # Get latest code from GitHub (today's discussion sections)
# ... code some features ...
cargo run # Demo your new feature
cargo test # run your tests
git add src/main.rs # Stage your changes
git commit -m "Add awesome feature" # Save your work
git push # Share with the team
For when your UI just won’t cut it
Confused by “invisible files” and folders?
ls -la
Need to find a file where you wrote something a while ago?
grep -r "that thing I wrote 6 months ago"
Modify lots of files at once?
# Rename 500 photos at once
for file in *.jpg; do mv "$file" "vacation_$file"; done
# Delete all files older than 30 days
find . -type f -mtime +30 -delete
“Why is my computer fan running like it’s about to take off?”
df -h # See disk space usage immediately
ps aux | grep app # Find that app that's hogging memory
top # Live system monitor
In other words, the command line provides:
- Speed: Much faster for repetitive tasks
- Precision: Exact control over file operations
- Automation: Commands can be scripted and repeated
- Remote work: Essential for server management
- Development workflow: Many programming tools use command-line interfaces
The file system and navigation
Everything starts at the root
Root Directory (/):
In Linux, the slash character represents the root of the entire file system.
(On a Windows machine you might see “C:" but on Linux and MacOS it is just “/”.)
(We’ll talk more about Windows in a minute)
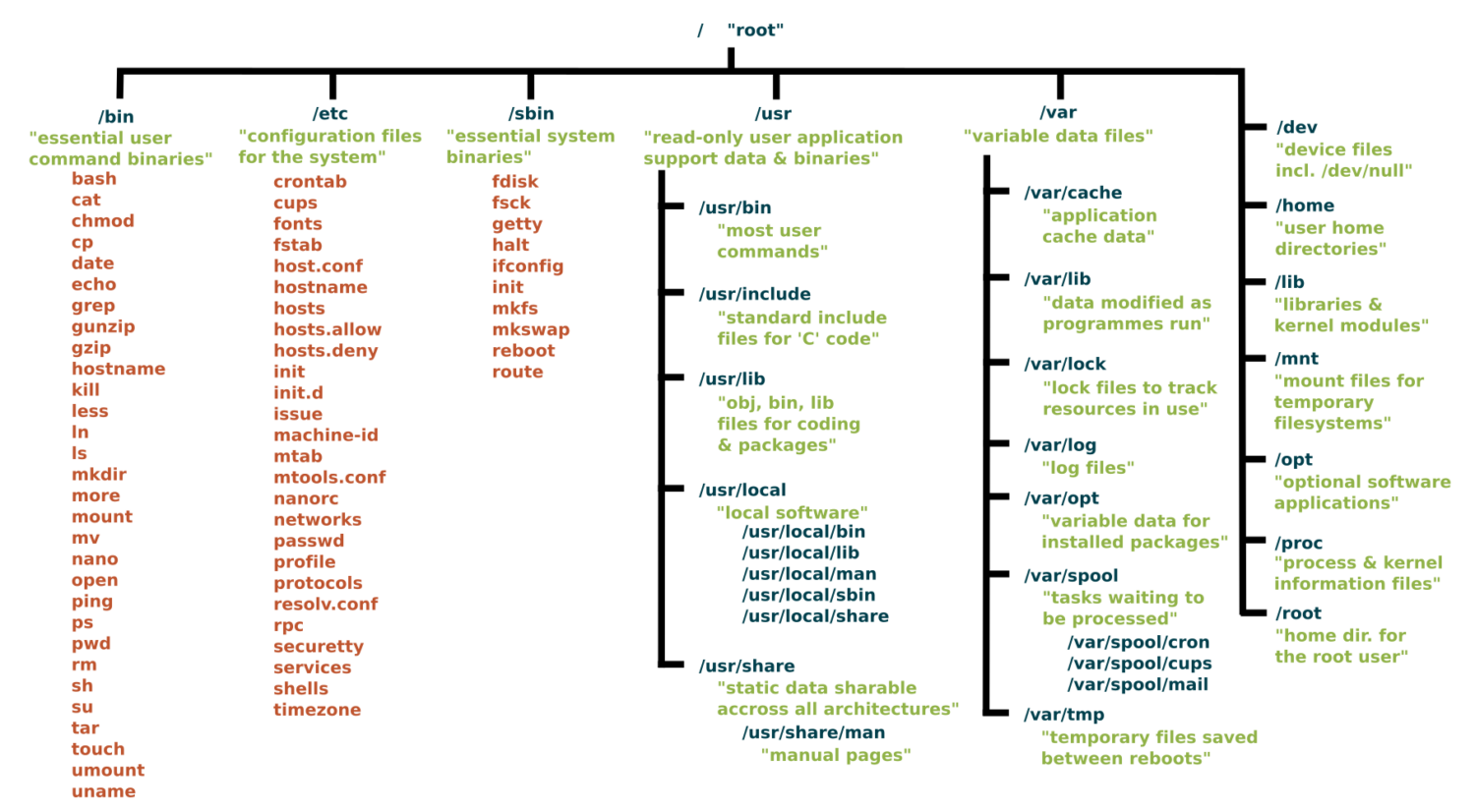
Key Directories You’ll Use:
/ # Root of entire system
├── home/ # User home directories
│ └── username/ # Your personal space
├── usr/ # User programs and libraries
│ ├── bin/ # User programs (like cargo, rustc)
│ └── local/ # Locally installed software
└── tmp/ # Temporary files
Navigation Shortcuts:
~= Your home directory.= Current directory..= Parent directory/= Root directory
Let’s take a look / basic navigation demo
Demo time! First let’s look at the command prompt…
Maybe half of your interactions with the shell will look like:
pwd # Print working directory
ls # List files in current directory
ls -a # List files including hidden files
ls -al # List files with details and hidden files
cd directory_name # Change to directory
cd .. # Go up one directory
cd ~ # Go to home directory
Tips:
- Use
Tabfor auto-completion (great for paths!) - Use
Up Arrowto access command history - Try
control-cto abort something running or clear a line - You can’t click into a line to edit it, use left/right arrows (or copy-paste)
What’s going on here?
The command line takes commands and arguments.
ls -la ~
The grammar is like a command in English: VERB (NOUN) (“eat”, “drink water”, “open door”)
ls is the command, -la and ~ are arguments.
Flags / Options
Special arguments called “options” or “flags” usually start with a dash - and can be separate or combined. These are equivalent:
ls -la
ls -al
ls -a -l
ls -l -a
BUT they typically need to come before other arguments:
ls -l -a ~ # works!
ls -l ~ -a # does not work
Winblows (or is it Windows?)
If you use Windows, I am sorry for you.
macOS and Linux are both built on top of Unix, so they share many similarities.
Windows is entirely different
dirinstead oflscopyandmoveinstead ofcpandmv
Thankfully, Windows decided to support the same language as Unix, e.g. via PowerShell and the Linux subsystem for Windows.
We strongly recommend Windows users install a terminal with
bashso we can speak the same language. Git comes with a Git Bash terminal built in!
One thing is unavoidable: different paths
/vsC:\Users\(vote for which is a back slash!)- This incompatibility has caused more suffering than metric vs imperial units.
Essential Commands for Daily Use
The rest of the 80% of bash commands you will mostly ever use
Demo time!
mkdir project_name # Create directory
mkdir -p path/to/dir # Create nested directories
touch notes.txt # Create empty file
echo "Hello World" > notes.txt # Overwrite file contents
echo "It is me" >> notes.txt # Append to file content
cat filename.txt # Display entire file
head filename.txt # Show first 10 lines
tail filename.txt # Show last 10 lines
less filename.txt # View file page by page (press q to quit)
nano filename.txt # Edit a file
cp file.txt backup.txt # Copy file
mv old_name new_name # Rename/move file
rm filename # Delete file
rm -r directory_name # Delete directory and contents
rm -rf directory_name # Delete dir and contents without confirmation
Understanding ls -la Output
-rw-r--r-- 1 user group 1024 Jan 15 10:30 filename.txt
drwxr-xr-x 2 user group 4096 Jan 15 10:25 dirname
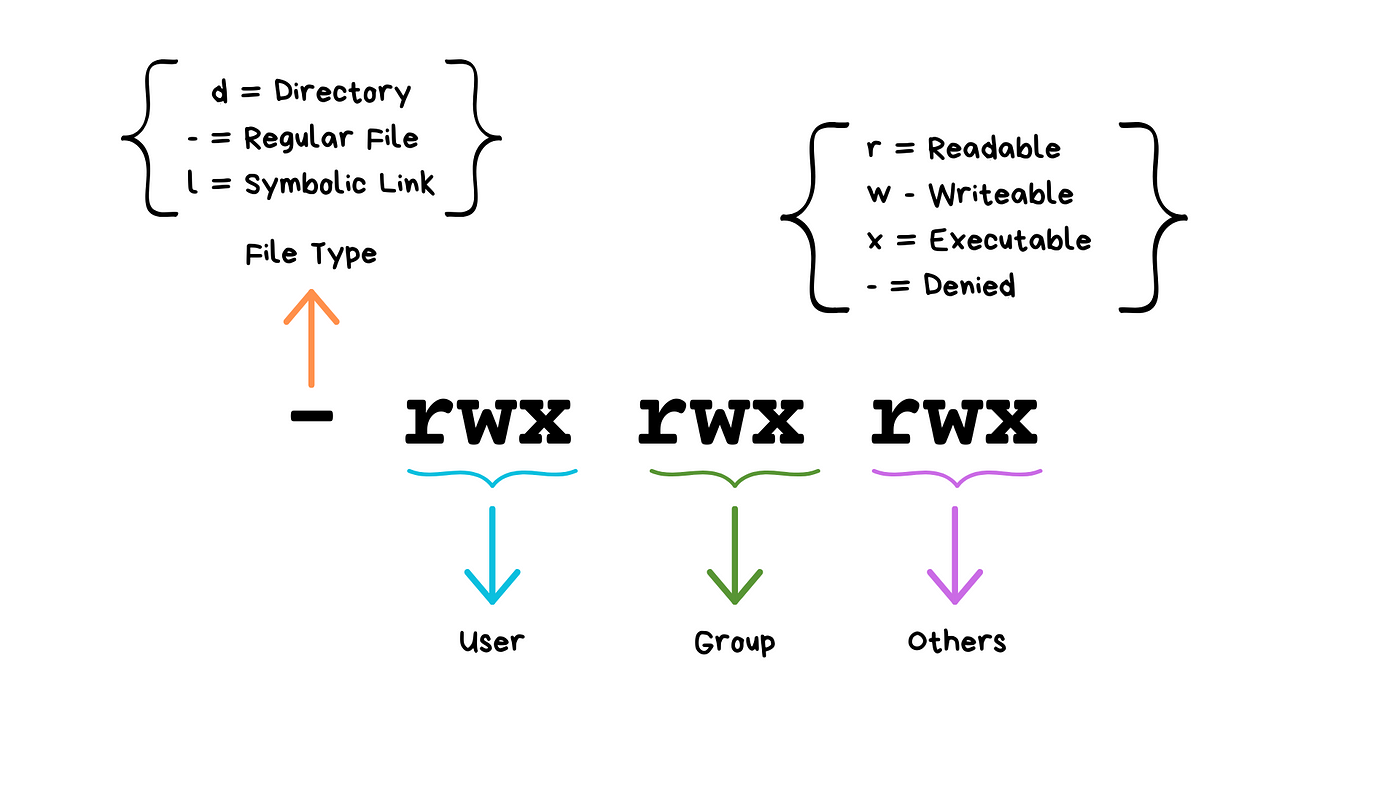
(Don’t worry about “groups”!)
We will see these kinds of permissions again in Rust programming!
Common Permission Patterns
rw-r--r--: Files you can edit, others can readrwxr-xr-x: Programs you can run, others can read/runrw-------: Private files only you can access
Don’t have permission?
You can use sudo!
sudo rm <protected_file> # removes file even if you do not have permissions
Combining Commands with Pipes
ls | grep ".txt" # List only .txt files
cat file.txt | head -5 # Show first 5 lines of file
ls -l | wc -l # Count number of files in directory
# Find large files
ls -la | sort -k5 -nr | head -10
# Count total lines in all rust files
cat *.rs | wc -l
# Save output of command in a file called `results.txt`
ls -la > results.txt
ls -la >> results.txt # append
How does Shell find your commands and programs
cargo --version # uses our earlier installation of Rust
firefox # opens firefox!
When you execute a command, shell looks for an executable file with that exact name in specific locations (folders).
which cargo
which firefox
These specific locations are defined by the PATH environment variable.
echo $PATH
Question: Say we run a new command and get an error that says the shell cannot find it or recognize it. What could the reasons possibly be?
Shell scripts
Shell script files typically use the extension *.sh, e.g. script.sh.
Shell script files start with a shebang line, #!/bin/bash. They tell the computer which shell to use for that file!
#!/bin/bash
echo "Hello world!"
To execute shell script you can use the command:
source script.sh
In Class Activity
Part 1: Access/Install Terminal Shell
Directions for MacOS Users and Windows Users.
macOS Users:
Your Mac already has a terminal! Here’s how to access it:
-
Open Terminal:
- Press
Cmd + Spaceto open Spotlight - Type “Terminal” and press Enter
- Or: Applications → Utilities → Terminal
- Press
-
Check Your Shell:
echo $SHELL # Modern Macs use zsh, older ones use bash -
Optional: Install Better Tools (do this after class):
Install Homebrew (package manager for macOS)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Install useful tools
brew install tree # Visual directory structurebrew install ripgrep # Fast text search
Windows Users:
Windows has several terminal options. For this exercise we recommend Option 1, Git bash.
When you have more time, you might want to explore Windows Subsystem for Linux so you can have a full, compliant linux system accessible on Windows.
PowerShell aliases some commands to be Linux-like, but they are fairly quirky.
We recommend Git Bash or WSL:
-
Option A: Git Bash (Easier)
- Download Git for Windows from git-scm.com
- During installation, select “Use Git and optional Unix tools from the Command Prompt”
- Open “Git Bash” from Start menu
- This gives you Unix-like commands on Windows
-
Option B (do this after class): Windows Subsystem for Linux (or for short, WSL)
# Run PowerShell as Administrator, then: wsl --install # Restart your computer # Open "Ubuntu" from Start menu -
Option C (acceptable for today if you have to): PowerShell (Built-in)
- Press
Win + Xand select “PowerShell” - Note: depending on your version, some commands may differ from what we will show you (uses
dirinstead ofls, etc.) - Not recommended for this course (or life in general).
- Press
Verify Your Setup (Both Platforms)
Run each of these commands in your terminal of choice:
pwd # Should show your current directory
ls # Should list files (macOS/Linux) or use 'dir' (PowerShell)
which ls # Should show path to ls command (if available)
echo "Hello!" # Should print Hello!
Part 2: Bandit Challenge
Go to Gradescope and do the Lec2: Shell Commands exercise!
Command Line Cheat Sheet
Basic Navigation & Listing
Mac/Linux (Bash/Zsh) or Windows with Git Bash or Linux subsystem:
# Navigate directories
cd ~ # Go to home directory
cd /path/to/directory # Go to specific directory
pwd # Show current directory
# List files and directories
ls # List files
ls -la # List all files (including hidden) with details
ls -lh # List with human-readable file sizes
ls -t # List sorted by modification time
Windows (PowerShell/Command Prompt):
# Navigate directories
cd ~ # Go to home directory (PowerShell)
cd %USERPROFILE% # Go to home directory (Command Prompt)
cd C:\path\to\directory # Go to specific directory
pwd # Show current directory (PowerShell)
cd # Show current directory (Command Prompt)
# List files and directories
ls # List files (PowerShell)
dir # List files (Command Prompt)
dir /a # List all files including hidden
Get-ChildItem -Force # List all files including hidden (PowerShell)
Finding Files
Mac/Linux:
# Find files by name
find /home -name "*.pdf" # Find all PDF files in /home
find . -type f -name "*.log" # Find log files in current directory
find /usr -type l # Find symbolic links
# Find files by other criteria
find . -type f -size +1M # Find files larger than 1MB
find . -mtime -7 # Find files modified in last 7 days
find . -maxdepth 3 -type d # Find directories up to 3 levels deep
Windows:
# PowerShell - Find files by name
Get-ChildItem -Path C:\Users -Filter "*.pdf" -Recurse
Get-ChildItem -Path . -Filter "*.log" -Recurse
dir *.pdf /s # Command Prompt - recursive search
# Find files by other criteria
Get-ChildItem -Recurse | Where-Object {$_.Length -gt 1MB} # Files > 1MB
Get-ChildItem -Recurse | Where-Object {$_.LastWriteTime -gt (Get-Date).AddDays(-7)} # Last 7 days
Counting & Statistics
Mac/Linux:
# Count files
find . -name "*.pdf" | wc -l # Count PDF files
ls -1 | wc -l # Count items in current directory
# File and directory sizes
du -sh ~/Documents # Total size of Documents directory
du -h --max-depth=1 /usr | sort -rh # Size of subdirectories, largest first
ls -lah # List files with sizes
Windows:
# Count files (PowerShell)
(Get-ChildItem -Filter "*.pdf" -Recurse).Count
(Get-ChildItem).Count # Count items in current directory
# File and directory sizes
Get-ChildItem -Recurse | Measure-Object -Property Length -Sum # Total size
dir | sort length -desc # Sort by size (Command Prompt)
Text Processing & Search
Mac/Linux:
# Search within files
grep -r "error" /var/log # Search for "error" recursively
grep -c "hello" file.txt # Count occurrences of "hello"
grep -n "pattern" file.txt # Show line numbers with matches
# Count lines, words, characters
wc -l file.txt # Count lines
wc -w file.txt # Count words
cat file.txt | grep "the" | wc -l # Count lines containing "the"
Windows:
# Search within files (PowerShell)
Select-String -Path "C:\logs\*" -Pattern "error" -Recurse
(Select-String -Path "file.txt" -Pattern "hello").Count
Get-Content file.txt | Select-String -Pattern "the" | Measure-Object
# Command Prompt
findstr /s "error" C:\logs\* # Search for "error" recursively
find /c "the" file.txt # Count occurrences of "the"
System Information
Mac/Linux:
# System stats
df -h # Disk space usage
free -h # Memory usage (Linux)
system_profiler SPHardwareDataType # Hardware info (Mac)
uptime # System uptime
who # Currently logged in users
# Process information
ps aux # List all processes
ps aux | grep chrome # Find processes containing "chrome"
ps aux | wc -l # Count total processes
Windows:
# System stats (PowerShell)
Get-WmiObject -Class Win32_LogicalDisk | Select-Object Size,FreeSpace
Get-WmiObject -Class Win32_ComputerSystem | Select-Object TotalPhysicalMemory
(Get-Date) - (Get-CimInstance Win32_OperatingSystem).LastBootUpTime # Uptime
Get-LocalUser # User accounts
# Process information
Get-Process # List all processes
Get-Process | Where-Object {$_.Name -like "*chrome*"} # Find chrome processes
(Get-Process).Count # Count total processes
# Command Prompt alternatives
wmic logicaldisk get size,freespace # Disk space
tasklist # List processes
tasklist | find "chrome" # Find chrome processes
File Permissions & Properties
Mac/Linux:
# File permissions and details
ls -l filename # Detailed file information
stat filename # Comprehensive file statistics
file filename # Determine file type
# Find files by permissions
find . -type f -readable # Find readable files
find . -type f ! -executable # Find non-executable files
Windows:
# File details (PowerShell)
Get-ItemProperty filename # Detailed file information
Get-Acl filename # File permissions
dir filename # Basic file info (Command Prompt)
# File attributes
Get-ChildItem | Where-Object {$_.Attributes -match "ReadOnly"} # Read-only files
Network & Hardware
Mac/Linux:
# Network information
ip addr show # Show network interfaces (Linux)
ifconfig # Network interfaces (Mac/older Linux)
networksetup -listallhardwareports # Network interfaces (Mac)
cat /proc/cpuinfo # CPU information (Linux)
system_profiler SPHardwareDataType # Hardware info (Mac)
Windows:
# Network information (PowerShell)
Get-NetAdapter # Network interfaces
ipconfig # IP configuration (Command Prompt)
Get-WmiObject Win32_Processor # CPU information
Get-ComputerInfo # Comprehensive system info
Platform-Specific Tips
Mac/Linux Users:
- Your home directory is
~or$HOME - Hidden files start with a dot (.)
- Use
man commandfor detailed help - Try
which commandto find where a command is located
Windows Users:
- Your home directory is
%USERPROFILE%(Command Prompt) or$env:USERPROFILE(PowerShell) - Hidden files have the hidden attribute (use
dir /ahto see them) - Use
Get-Help commandin PowerShell orhelp commandin Command Prompt for detailed help - Try
where commandto find where a command is located
Universal Tips:
- Use Tab completion to avoid typing long paths
- Most shells support command history (up arrow or Ctrl+R)
- Combine commands with pipes (
|) to chain operations - Search online for “[command name] [your OS]” for specific examples
Rust and VSCode Setup
Lecture 2: Wednesday, May 20, 2026.
Code examples
This module will run you through the steps required to installed the tools we need for this course:
- The Rust compiler and package manager (called
cargo) - The VSCode IDE and its Rust analyzer plugin for developing Rust!
- Git.
It will also show you the basics of creating and running a Rust project using VSCode and the command line.
Rust Compiler, IDE, and git Setup
To get setup, follow these instructions and do not hesitate to ask us for help.
You should also install Git using these instructions.
How do you know if you have succeeded in setting up Rust
Use these steps to test that your setup is successfully.
To test your Rust (cargo) installation:
- Run the following command in your command line (Mac/Linux) or power shell (Windows):
cargo --version
The output should show cargo version 1.92.0 or later.
- Create a hello world Rust project by navigating to a folder of your choosing (e.g., your desktop) and running the following command via your command line (Mac/Linux) or power shell (Windows):
# make sure you are in the desktop directory/folder
cargo new hello_world --bin
- Run the hello world Rust project using:
# make sure you are in the desktop directory/folder
cd hello_world # change directory to inside of the hello_world project
cargo run # run the project
If successful, you should see the following output:
Hello, world!
Common issues
Windows
C++ Redistributable Package: You may not have Microsoft’s visual c++ redistributable package installed. If you do not, the Rust compiler
may appear to be installed successfully but fail to work when run. You can fix this error by installing this package from here.
Path Environment Variable: If you get an error saying that cargo cannot be found or is unrecognizable when you attempt to run cargo --version,
you must manually add %USERPROFILE%\.cargo\bin to your path environment variable. You can do that by following this video, but make sure
to add %USERPROFILE%\.cargo\bin instead of what the video uses (python directory).
Missing link.ex: You may not have the C++ build tools (including the linker) installed. If so, when you try to compile/run a Rust project, you will get an error about missing link.exe.
In this case, you will need to install the windows SDK and the MSVC C++ Build tools from https://visualstudio.microsoft.com/downloads/. Choose the latest version of both that is compatible with your machine.
Mac
Mac VSCode Command Line: The default command line in VSCode on Mac is Zsh which may give you some headache or not work. If so, you can change it to bash
which is friendlier for Rust using these instructions.
In-class Exercise: Rust and VSCode Basics
This module gives you some practice creating, editing, and running Rust projects.
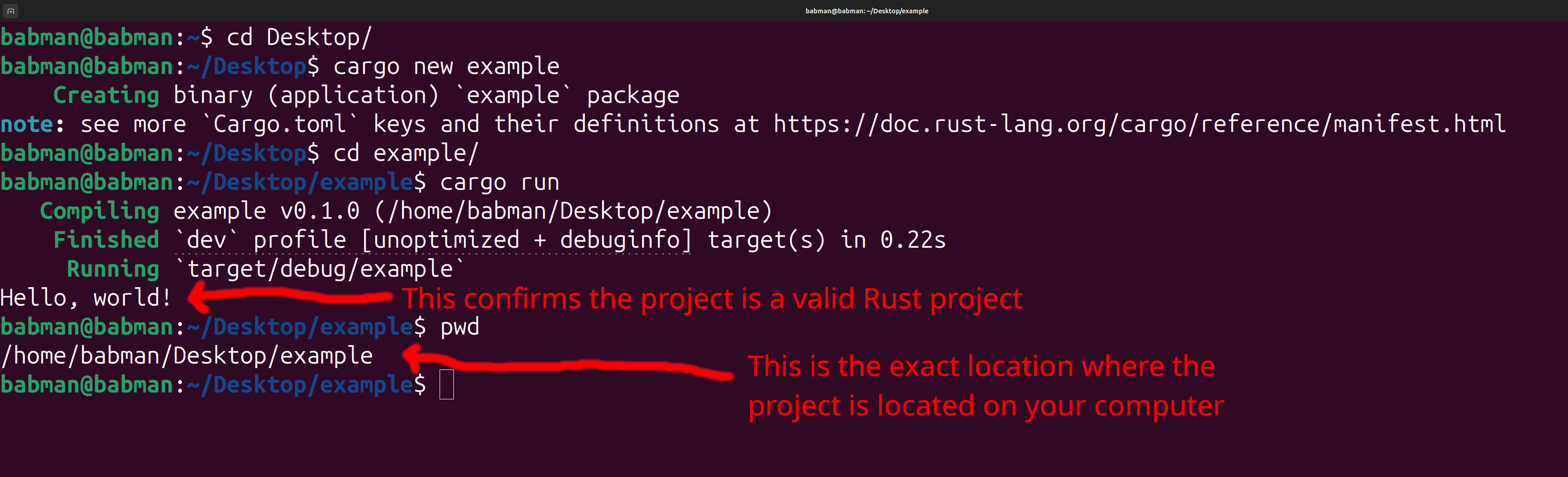
Step 1: Create the Project
We will create a project from the terminal / command line. Use Git Bash if you are on windows.
-
Open a terminal, and navigate to the folder where you would like your project to appear using
cd. -
Run
cargo new exampleto create a new project. In this case, we named this projectexample, but you can change the name to whatever you feel like. -
Confirm the project was created correctly by navigating to its folder using
cd exampleand running it usingcargo run. -
Use
pwdto the exact location where you created the folder.
You should see a similar output to the screenshot below, but the location of your project may be different.
Step 2: Open the project with VSCode
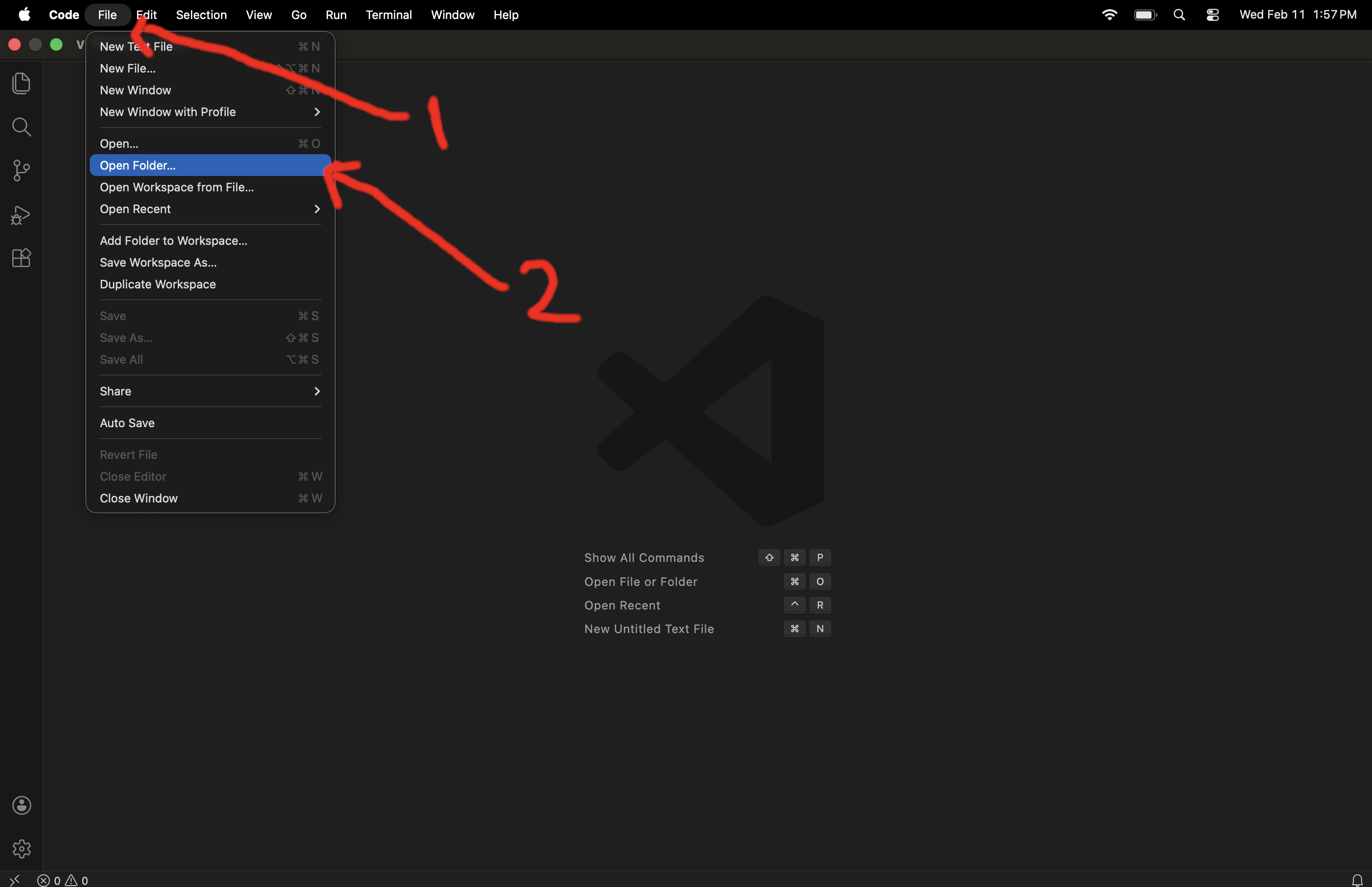
Open your VSCode, then use the file menu to click on open folder. You need to use open folder and not open.
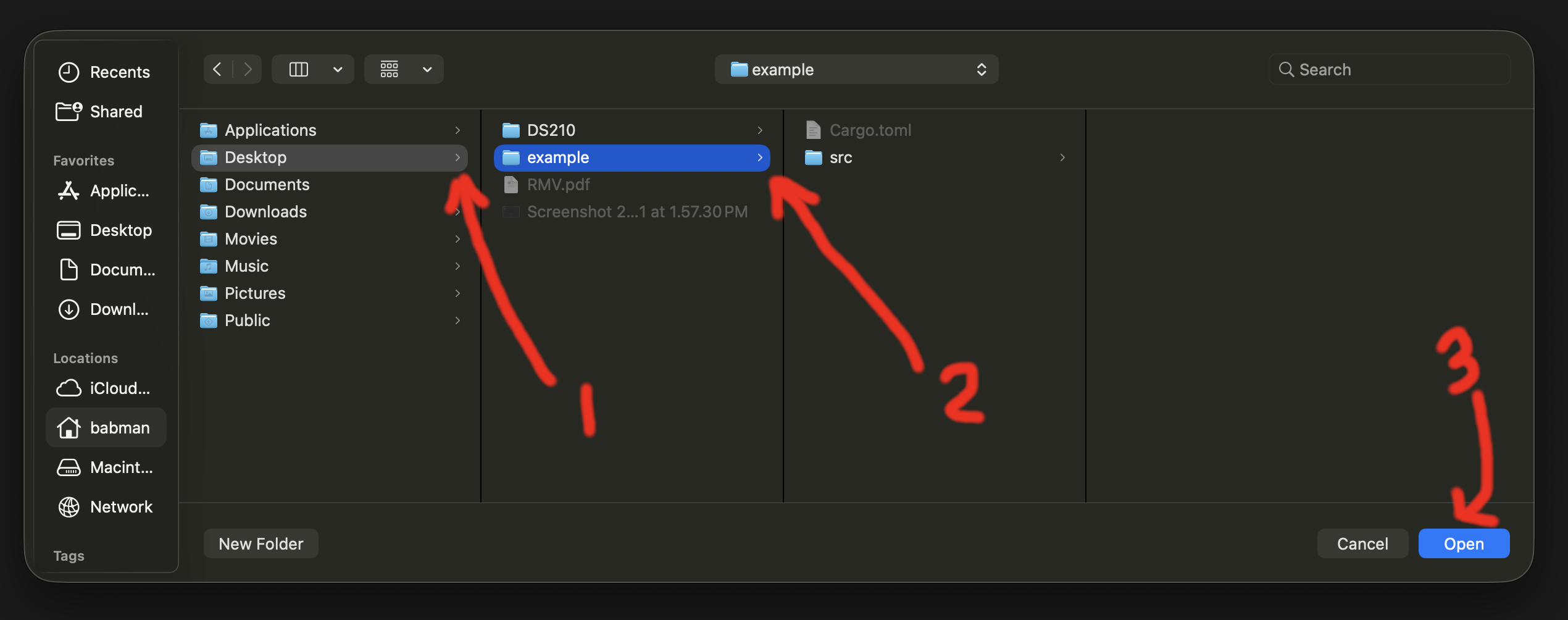
Then navigate to the location from step (4) above where you placed the project, and open the project’s folder.
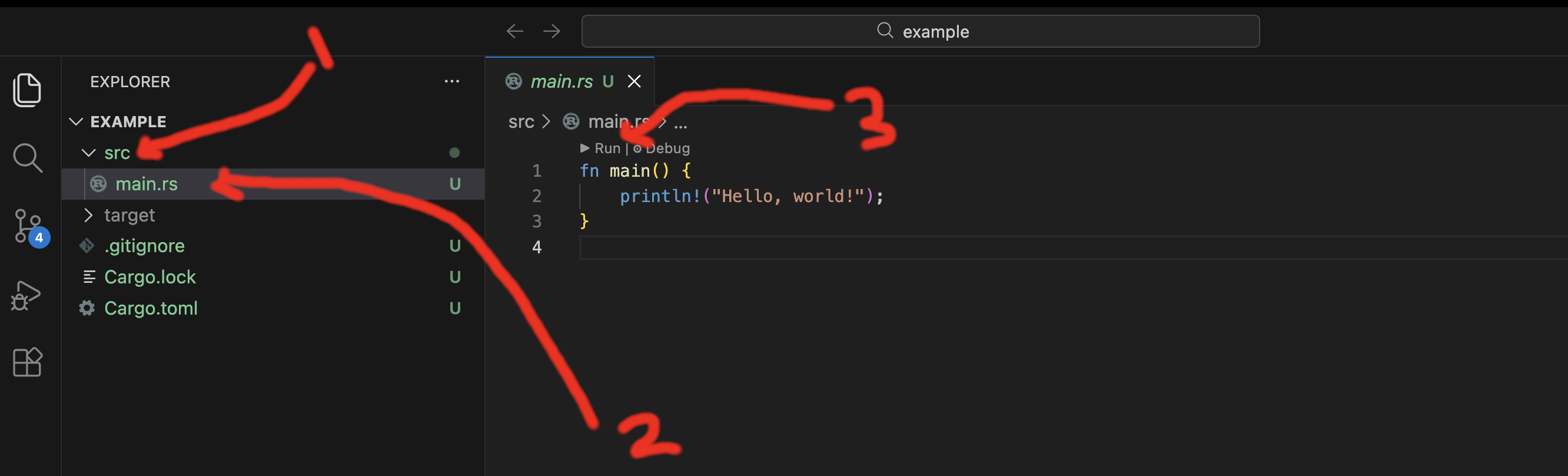
Finally, use the left navigation panel to look inside src and open file main.rs to see the code. You should see the content of the file open, as well as a run button
right on top of the main function. Click run to confirm it works successfully.
If you do not see the run button, double check that (1) rust analyzer is installed in VSCode, and (2) you used open folder and opened the correct folder – e..g, the example folder on your desktop.
Step 3: Modify and run the code
Change the code to the following:
fn main() { let x = 10; let y = 15; let sum = 10 + 15; println!("{x} + {y} = {sum}!"); }
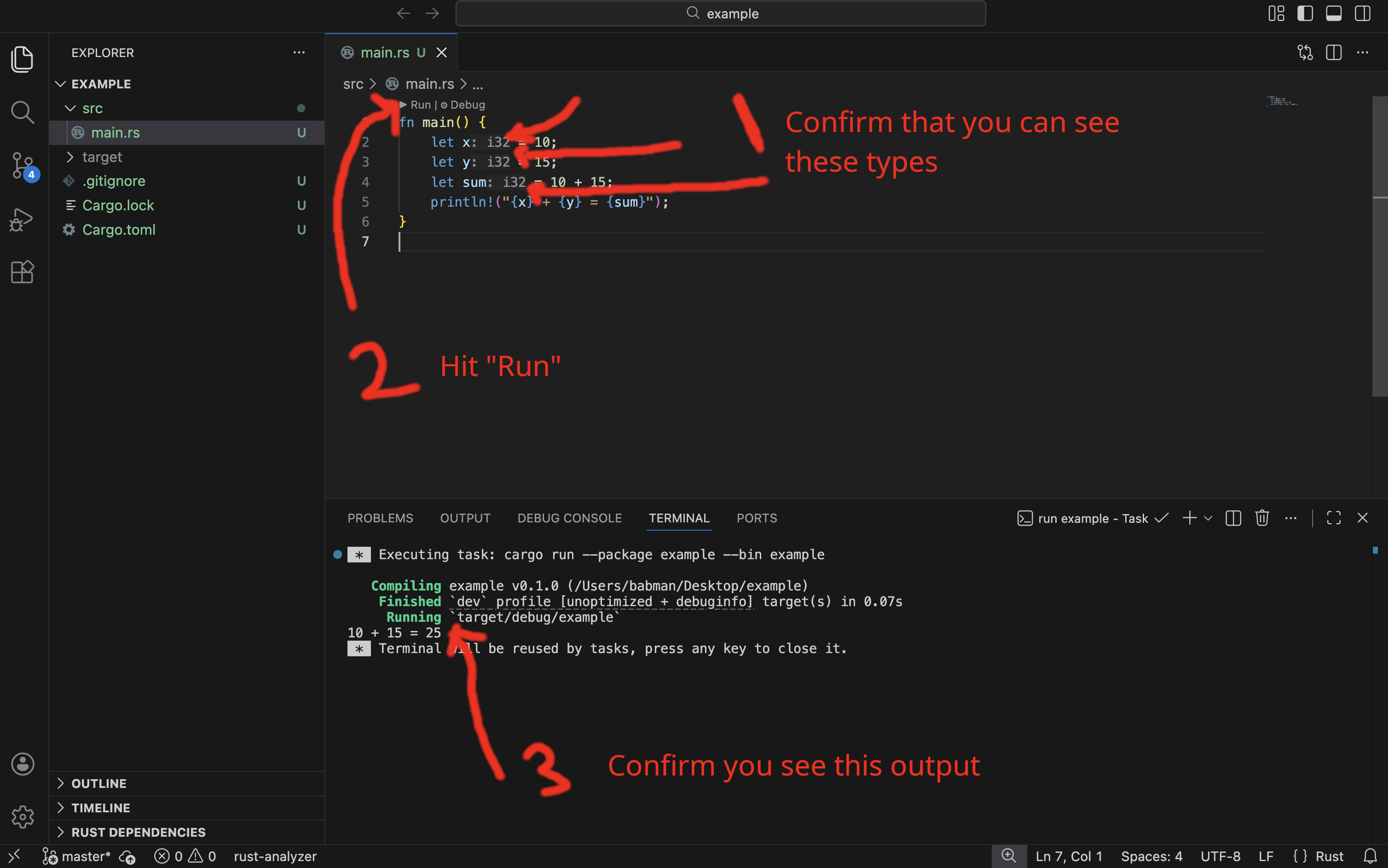
If you followed all the steps correctly, you will see VSCode add in the type of x, y, and sum automatically on your behalf, as shown in the screenshot below.
You can run the code from the command line using cargo run, and you can also run it from VSCode as below.
Rust Variables and Types
or how I learned to stop worrying and love the types1
Lecture 3: Thursday, May 21, 2026 and
Lecture 4: Tuesday, May 26, 2026.
Code examples
Rust is a statically typed programming language! Every variable must have its type known at compile time. This is a stark difference from Python, where a variable can take on different values from different types dynamically.
This has some really deep consequences that differentiate programming in Rust from that in Python.
To illustrate this better, let’s start with a simple motivating example from Python.
Motivating example
Let’s start with the following simple example from Python. Let’s say we have two Python lists names and grades.
The first stores the names of different students in a class. The second one stores their grades. These lists are index-aligned:
the student whose name is at names[i] has grade grades[i].
names = ["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]
grades = [ 0, 100, 95, 88, 99, 98, 97]
# Kinan's grade is 0, Kesar's grade is 99
Now, imagine we need to write some Python code to print the grade of a student given their name. Let’s say the name
of this target student is stored in a variable called target.
# Alternatively, the value of target might be provided by the
# user, e.g., via some nice UI
target = "Kesar"
Our first observation is that the grades and names are index-aligned. So to find the grade of “Kesar”,
we need to find the index of “Kesar” in names. Let’s do that using a helper function. Here’s a reasonable first attempt:
def find_index(target, names):
# iterate from 0 up to the length of names.
for i in range(len(names)):
if target == names[i]:
return i
Now, we can use find_index to retrieve the grade of “Kesar” as follows.
target = "Kesar"
index = find_index(target, names)
print(grades[index])
This indeed works! and if we run it, we will see the correct output.
99
The code will also work for many other values of target, e.g. “Kinan”, “Matt”, “Emir”, etc.
However, what about if we search for a target who is not in names? For example, target = tom?
In this case, find_index never finds a name equal to target, and so its for loop finishes without ever returning any i.
def find_index(target, names):
for i in range(len(names)):
# when target = 'Tom'
# then this condition is False for all elements in names
if target == names[i]:
# this is never reached for target = 'Tom'
return i
# instead, when target='Tom' the execution reaches this point.
# What should we return here?
return ?????
A good follow up question is what should find_index return in such a case?
Discuss this with your neighbor and come up with a candidate value!
Option 1: return -1
Many languages, e.g., Java, use -1 to indicate having not found something. Let’s consider what happens
if we try that out in our Python example. In this case, our find_index function becomes:
def find_index(target, names):
for i in range(len(names)):
if target == names[i]:
return i
return -1
So what would happen in this case if we search for a target that does not exist?
target = "Tom"
index = find_index(target, names)
print(grades[index])
In this case, find_index returns -1. So, index is equal to -1, and we print grades[-1]. In python, an index of -1
corresponds to the last element in the list. So, our program will print the last grade in the list.
97
This is no good! Tom’s grade is not 97! That’s Emir’s grade. In fact, Tom has no grade at all!!! This kind of silent problem is the worst kind you can have, because you may not even realize that it is a problem. Imagine if there were thousands of students. You run the code and see this output. You may not realize that the target you were looking for isn’t there (or that you made a typo in the student’s name), and think that the output is accurate!
You can find the code for this option here.
Option 2: return “Not found”
A different option would be to return “Not found” or some special kind of similar message.
This is curious! find_index now sometimes returns an index (which is a number, i.e., of type int), and sometimes returns a string (in Python, that type is called str)!
def find_index(target, names):
for i in range(len(names)):
if target == names[i]:
return i
return "Not found"
target = "Tom"
index = find_index(target, names)
print(grades[index])
In this case, index is equal to `“Not found”. So, our last line is equivalent to saying:
grades["Not found"]
This makes no sense! Imagine someone asks you to look up an element in a list at position “Not found”, or position “hello!”, or any other string. What would you do? I would freak out. So does Python, running this code results in the following error:
TypeError: list indices must be integers or slices, not str
In my opinion, this is a little better than option 1. At least, it is visible and obvious that something wrong went on. But it is still not good.
You can find the code for this option here.
Option 3: return “Not found” then manually check the type
How about we check the type of whatever find_index returns before we attempt to access the list of grades?
It turns out we can ask Python to tell us what type a variable (or any value or expression) has! This happens at runtime: we cannot actually determine the type ahead of time. Only when the program is executing/all inputs have been supplied.
def find_index(target, names):
for i in range(len(names)):
if target == names[i]:
return i
return "Not found"
target = "Tom"
index = find_index(target, names)
if type(index) == int:
print(grades[index])
else:
print('not found')
If we run this code, the output we see is:
not found
Finally, we have a solution that works! If the name is in the list, the program will print the grade, and otherwise
it will print not found.
One of the reasons we had to go through all these steps is that Python has dynamic typing. The same function or variable may return or contain different types when you run the program with different inputs.
Furthermore, neither Python nor our program help us out by telling us what the possible types are, or that we checked all of them. We have to figure this out ourselves, and remember to do the checking manually.
You can find the code for this option here.
What about Rust?
Let’s look at the same problem in Rust. The beginning is similar to the Python code.
fn main() { let names = vec!["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]; let grades = vec![ 0, 100, 95, 88, 99, 98, 97]; let target = "Matt"; // we need to find Matt's grade }
However, we can already see one difference. If you look at this code in a Rust IDE, such as VSCode, you will notice that it automatically fills in the type of each variable. As shown in the screenshot below.
For example, VScode tells us that the type of target is a string (Rust calls this &str, more on the & part later), and the type of grades is Vec<i32>, in other words, a vector (which is what Rust calls
Python lists) that contains i32s in it!
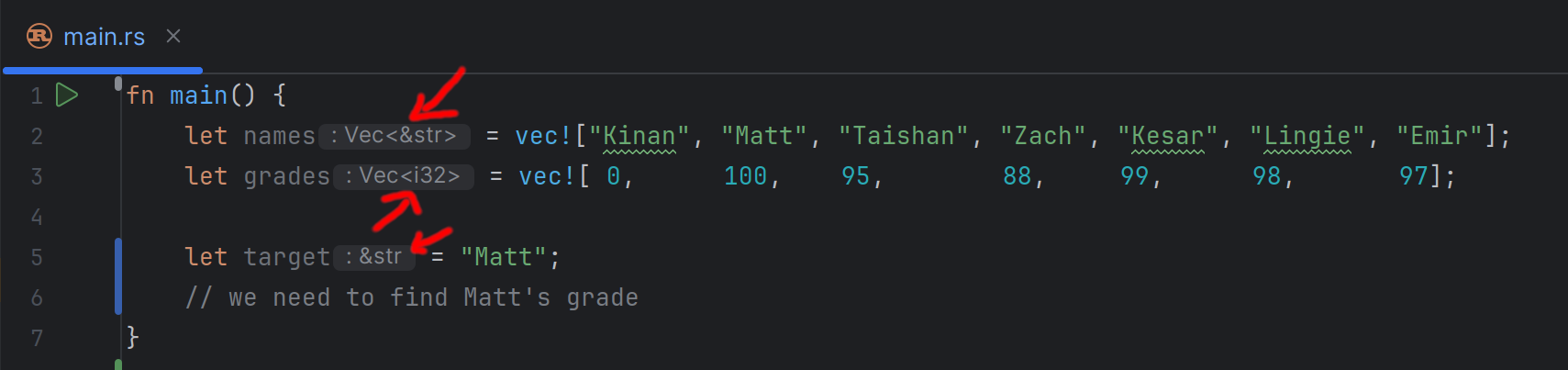
This is quite cool. Not only do we know the type of every variable. We also know information about any other elements or values inside that variable. E.g., the type of the elements inside a vector!
It turns out, we can also write these types out explicitly ourselves in the program. For example:
fn main() { let names: Vec<&str> = vec!["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]; let grades: Vec<i32> = vec![ 0, 100, 95, 88, 99, 98, 97]; let target = "Matt"; // we need to find Matt's grade }
Furthermore, if we specify types that are inconsistent with the values assigned to a variable, we will get a compiler error!
fn main() { // This should not work: "Kinan" is a string, not an i32. let target: i32 = "Kinan"; }
error[E0308]: mismatched types
|
| let target: i32 = "Kinan";
| --- ^^^^^^^ expected `i32`, found `&str`
This is a consequence of an important design decision in Rust. It follows a strong static typing philosophy, where every variable (and expression) needs to have a single type that is known statically. In other words, a type that is determined at compile time before the program runs and does not change if you run the program with different inputs again.
Fortunately, Rust has support for type inference. With type inference, we do not have to write out every type in the program explicitly. Instead, we can often (but not always!) skip the types, and let the language deduce it automatically. Hence, VSCode being able to show us the types in the example above.
Now, let’s move on to the next step in the program. We need to implement a find_index function in Rust.
In Rust, function definitions (or more accurately, function signatures) look like this:
fn find_index(target: &str, names: Vec<&str>) -> usize { // the body of the function with all its code goes here. todo!("will implement later") }
There are a few important differences between this and Python:
- Rust uses
fn(short for function) to indicate a function definition, Python usesdef(short for definition). - Every argument to the function must have an explicitly defined type in Rust. For example, we explicitly state that
targethas type&str(i.e. string). - The function must state explicitly what type of values it returns (if any). This is the
-> usizepart, which tells us that this function return values of typeusize(Ausizein Rust is a type that describes non-negative numbers that can be used as indices or addresses on the computer).
Now, we can try to fill in the function body, mimicking the same logic from Python but using Rust syntax.
fn find_index(target: &str, names: Vec<&str>) -> usize { for i in 0..names.len() { if target == names[i] { return i; } } return "Not Found"; }
We can see a few syntax differences that we already covered earlier in class:
- Python relies on
:and indentation to specify where a code block starts and end (e.g., the body of a function, for loop, or if statement). Rust instead uses{and}. - Rust’s syntax for ranges is
<start>..<end>, e.g.,0..names.len(), while Python usesrange(0, len(names)).
However, a deeper difference has to do with the types. The code above does not compile in Rust, and gives us the following error.
error[E0308]: mismatched types
|
| fn find_index(target: &str, names: Vec<&str>) -> usize {
| ----- expected `usize` because of return type
| return "Not Found";
| ^^^^^^^^^^^ expected `usize`, found `&str`
This makes sense. We had already promised Rust that find_index would only return elements that have type usize, but then tried to return “Not Found”, a string!
We can try to change the function signature to return strings, e.g. with -> &str. However, this results in a different error: “Not found” is now OK, but return i is not, since i
is not a string (and is in fact a usize).
So, it appears as if we are in a catch 22: no matter what type we chose to specify as the return, we will sometimes try to return a value of a different type.
One quick and dirty fix is to always return usize. So, instead of returning “Not Found”, we can return some special number that indicates that the value is not found. We can try returning -1, but we will get a similar error,
since -1 is not a usize (it cannot be negative!). The best we can do is return names.len() and hope that callers manually check this value with an if statement before using it.
fn find_index(target: &str, names: Vec<&str>) -> usize { for i in 0..names.len() { if target == names[i] { return i; } } return names.len(); } fn main() { let names = vec!["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]; let grades = vec![ 0, 100, 95, 88, 99, 98, 97]; let target = "tom"; let index = find_index(target, names); if index < grades.len() { let grade = grades[index]; println!("{grade}"); } else { println!("Not found"); } }
This code works, although it is not an ideal approach. What if we forgot to add in the if index < grades.len() check? The program would crash with an out of range error. We will see how we can improve it next.
You can find the code for this option here.
Using Option
The main challenge we face is that find_index needs to return some special value/type to indicate not finding something, but only rarely. Rust does not let us return different type dynamically the same way Python does.
So, we need a way to let Rust understand, using types, that there are different cases that find_index may encounter and return.
Fortunately, Rust already has a type builtin that does this. The Option type.
fn find_index(target: &str, names: Vec<&str>) -> Option<usize> { // code goes here todo!("will implement later") }
This tells Rust that find_index will sometimes (i.e., optionally) return some usize, but it may sometimes not find anything and instead return nothing. Option is a special kind of type (called an Enum, we will learn more about those later) that
can only be constructed in two ways: either, it is a None which indicates that it is empty, or it is a Some(<some value>) which indicates that it has something in it. Furthermore, following Rust’s philosophy, the type of that something is known,
in this case, usize.
If we had alternatively said Option<&str> or Option<i32> (or even Option<Option<i32>>), then the type of that something would correspondingly be a string, an i32 number, or another option that may have an i32 number in it, respectively.
Great. Now we can re-write the above function, and if we find no matches, we can return None, while if we find some matching index i, we return Some(i).
fn find_index(target: &str, names: Vec<&str>) -> Option<usize> { for i in 0..names.len() { if target == names[i] { return Some(i); } } return None; }
This is much better!
The last thing we now need to consider is how we call find_index. Previously, we wrote let i = find_index(target, names);, back then VSCode would helpfully tell us that i has type usize.
Now however, it has type Option<usize>. So we cannot use it the same way as before. For example, Rust gives us an error if we try to do grades[i], since i is an Option! Which makes sense,
what does it mean to look up a value in a list by an index that may or may not exist?
[E0277]: the type `[i32]` cannot be indexed by `Option<usize>`
|
| let grade = grades[i];
| ^ slice indices are of type `usize` or ranges of `usize`
Python cannot do this! Remember how it did not inform us that the index could have been None (in option 2) or a string (in option 3). In Python, we had to manually remember this fact, and manually check which case it was in the code. But, because Rust knows all the types it can remind us of this if we forget.
We can fix our code as follows:
fn find_index(target: &str, names: Vec<&str>) -> Option<usize> { for i in 0..names.len() { if target == names[i] { return Some(i); } } return None; } fn main() { let names = vec!["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]; let grades = vec![ 0, 100, 95, 88, 99, 98, 97]; let target = "tom"; let i = find_index(target, names); // i has type Option<usize> if i.is_none() { println!("Not found"); } else { let value = i.unwrap(); // value has type usize let grade = grades[value]; println!("{grade}"); } }
Take a closer look at the following:
- We can check whether an Option is None or Some using
is_none(). - We can use
.unwrap()to extract the value inside the Option when it is Some.
This code does the job, and you can find it at here.
One reasonable question is what would happen if we use unwrap() on an Option that is None. For example, what do you think would happen if we run this code? (try running it with the Rust playground to confirm your answer).
fn main() { let i: Option<usize> = None; println!("This is crazy, will it work?"); let value = i.unwrap(); println!("it worked!"); println!("{value}"); }
Our program runs, but crashes with an error mid way through:
This is crazy, will it work?
thread 'main' (39) panicked at src/main.rs:4:19:
called `Option::unwrap()` on a `None` value
match Statements
The previous code is almost the ideal approach, but it suffers from one problem. We may make a mistake while checking the cases that an Option (or indeed, other types like Option) may have,
and as a result, call unwrap() when we should not, thus causing an error and a crash.
In fact, unwrap() is really really dangerous! It is almost always better not to use it.
Thankfully, Rust offers us a unique and helpful feature. By using match, we can check all the cases of an Option or similar type, exhaustively and without danger. Here is an example:
fn find_index(target: &str, names: Vec<&str>) -> Option<usize> { for i in 0..names.len() { if target == names[i] { return Some(i); } } return None; } fn main() { let names = vec!["Kinan", "Matt", "Taishan", "Zach", "Kesar", "Lingjie", "Emir"]; let grades = vec![ 0, 100, 95, 88, 99, 98, 97]; let target = "tom"; let i = find_index(target, names); match i { None => println!("Not found"), Some(value) => { let grade = grades[value]; println!("{grade}"); } } }
So, how does match work?
- You typically match on a value whose type has different cases, like
Option(more accurately, on Enums, which we will explain more in detail later in the course). - You specify the value you want to match on immediately after
match. In the above, we are matching onibecause we saidmatch i { ... }. matchhas a corresponding{and}, like a function, loop, or if statement body.- Within that body, we list the different cases that the value/type may have. These have the following shape:
<case> => <code>,- if the case has nothing in it, we can just write down its name, e.g.,
None. If it has a value, we can tell Rust to put that value in a variable for us and give it a name, for example, ifihas something in it, Rust will put it insidevalue. - the code may be a single statement (like the print in
None) or many statements (line withSome). In the latter case, we need to use{and}to specify where the code block starts and ends. - Finally, you must use
,to separate the different cases.
- if the case has nothing in it, we can just write down its name, e.g.,
In my opinion, this is the best solution we have seen. You can find it here.
Why do I think it is the best solution? Because, Rust helps us a lot when using a match statement. Specifically, if we forget a case, Rust will give us a compile error and tell us exactly what case(s) we missed.
For example, imagine we wrote this code (omitting the None case because we forgot):
match i {
Some(value) => {
let grade = grades[value];
println!("{grade}");
}
}Rust will give us the following error (and in fact VSCode will suggest to add the fix for us!).
error[E0004]: non-exhaustive patterns: `None` not covered
|
| match i {
| ^ pattern `None` not covered
HashMaps
The code we came up with works alright for cases where we want to look up one student’s grade. However, imagine we needed to look up the grades for several students, or to do so repeatedly.
For every lookup, we have to call find_index again and loop through all the names again. (We call this a linear time
algorithm or O(n). We will get to the details of this later.)
A HashMap gives us a much faster alternative. It allows us to look up data by a key of our choosing — so we can use the student’s name directly as the key to get their grade, without any searching. You have already seen this concept in Python, where it is called a dictionary.
In addition to having better performance at runtime, using a HashMap here will also simplify the code! We will not need to search for the target among all the names, since a HashMap provides us with a function that can retrieve a value by key (i.e., grade by name) directly!
HashMap is provided by Rust’s standard library, but we have to import it with use std::collections::HashMap;.
Creating a HashMap
We can create a HashMap and populate it all at once using HashMap::from:
use std::collections::HashMap; fn main() { let map = HashMap::from([ ("Kinan", 0), ("Matt", 100), ("Taishan", 95), ("Zach", 88), ("Kesar", 99), ("Lingjie", 98), ("Emir", 97) ]); }
Each entry is a (<key>, <value>) pair. Here, the keys are student names (&str) and the values are their grades (i32).
Getting a value from a HashMap
We can retrieve a value by key using map.get(<key>). For example, map.get("Kesar").
What do you think the type of the result is? Hint: put this code in VSCode and see what it tells you!
The result is not just a number. Think about what would happen if we looked up a key that does not exist in the map,
e.g., map.get("Tom"). This is the same problem we encountered before with find_index!
The Rust developers have already thought of this: map.get(...) returns an Option. So if we have a
HashMap<&str, i32>, then map.get(...) returns an Option<&i32>2.
We already know how to handle Option types — we can use a match statement:
use std::collections::HashMap; fn main() { let map = HashMap::from([ ("Kinan", 0), ("Matt", 100), ("Taishan", 95), ("Zach", 88), ("Kesar", 99), ("Lingjie", 98), ("Emir", 97) ]); let target = "tom"; let grade = map.get(target); match grade { Some(value) => println!("{value}"), None => println!("not found") } let target = "Kesar"; let grade = map.get(target); match grade { Some(value) => println!("{value}"), None => println!("not found") } }
What would happen in Python if you attempt to access a dictionary using a non-existing key? e.g.,
map["tom"]?
You can find the full code here.
Running and Experimenting with The code Examples
You can run most of the example within the lecture notes directly, using the run icon at the top right corner of the code block.
You can also retrieve the code from the course’s GitHub repository and run it locally in your machine:
-
Either download the code as a zip from the GitHub repository, or clone it using git:
git clone https://github.com/rust4ds/ds210-sum26-code.git -
Open
module_5_types_and_functions/4_hash_mapfolder in your VSCode (or any of the other example folders). -
You can run and edit the code as you wish using VSCode or from the terminal!
-
Also, take a look at what types VSCode shows for the different variables, and see if you can understand why they have these types!
-
If you did not get this reference, you are missing out on one of the greatest movies of all time. Watch it. ↩
-
Do not worry about these pesky
&s for now. We will go over them later in the course. ↩
Comparing and Evaluating Programs
Lecture 4: Tuesday, May 26, 2026, and
Lecture 5: Wednesday, May 27, 2026.
Code examples
What Makes a Good Program – How To Evaluate Different Programs That Do The Same Thing
One problem can usually be solved in many many different ways. These differences may stem from following an entirely different algorithm for how to solve the problem, structuring and organizing the code in a different way, or even the unique “artistic” style of the program author.
So, if you are looking at different programs that aim to solve the same problem, how do you know which one is better? In other words, how do you chose which one to use? This also applies to when you are developing the solution yourself. You may brainstorm different competing approaches, but you will eventually have to choose one to implement.
There are several metrics by which you can judge a program. Sometimes, these metrics may be at odds, and it is up to you to prioritize some over others based on the context of the problem at hand. These metrics include:
- Correctness: Does the program actually solve the problem? Does it solve it correctly for all possible inputs? Does it produce accurate results consistently? This is often (but not always) non-negotiable, and in this course, you are always expected to implement correct programs.
- Performance: How fast does the program run? Faster programs are often desirable because they save money! However, this is not always clear cut to evaluate: some programs may be faster for certain kinds or sizes of inputs while being slower for others.
- Memory consumption: How much memory/space does the program consume? This often has implications on program performance, but can be important on its own if dealing with really large inputs that strain the available memory on a computer.
- Readability: Is the program easy to understand by someone else if they read it? Is the main idea behind and why it works clear? This is often important in the real world where programs need to be developed and maintained by a team of different programmers.
- Ease of Development: How complex is it to implement this program? How long would it take the programmer to implement, optimize, test, and document the program to a satisfactory degree?
- Ease of Maintenance or Updating: How easy is it to update the solution if the problem is changed slightly or if the circumstances change a little? Can the solution be generalized to other similar problems or other contexts?
Some of these metrics are more objectives than others. E.g., you can design experiments to benchmark exactly how long a program takes to execute in different setups and workloads (performance), but two reasonable programmers may disagree on how readable or how much effort is required to develop a particular program.
We will explore this further using two examples.
Example 1 - Contains Duplicate
Remember the contains duplicate problem that you had to solve for homework 2.
In this problem, we are given a vector with n elements, and we need to discover if some element(s) in it are duplicated.
For example, the vector [1, 2, 3, 1, 5] has a duplicate (1) but [1, 3, 2, 5, 4] does not.
The Solutions
There are different ways of solving this problem, we will explore three approaches which you can find in the courses’ code repository.
Solution 1
Our first idea is to use sorting to order the elements of the vector.
For example, if our input is [1, 2, 3, 1, 5], we can sort it so that it becomes
[1, 1, 2, 3, 5].
Note that after sorting, any duplicates would appear consecutively in the vector. Thus, we can simply check if any consecutive elements are the same.
#![allow(unused)] fn main() { fn contains_duplicate(mut numbers: Vec<i32>) -> bool { numbers.sort(); for i in 0..numbers.len() - 1 { if numbers[i] == numbers[i+1] { return true; } } return false; } }
Solution 2
A different idea is to count how many times each element appears in the vector.
Essentially, we can construct a hash map that maps each element to how many times it appears in the vector.
For example, if the input vector was [1, 2, 3, 1, 5], we would construct the following counts map:
{
1: 2,
2: 1,
3: 1,
5: 1
}
After constructing this map, finding out whether there are duplicates becomes easy: we can look at
all the elements and their counts, and check if any have a count that is greater than 1.
Here’s an implementation of this idea below:
#![allow(unused)] fn main() { use std::collections::HashMap; fn contains_duplicate(numbers: Vec<i32>) -> bool { // Construct a map from element to its count let mut map = HashMap::new(); for num in numbers { let value_in_map = map.get(&num); match value_in_map { None => { map.insert(num, 1); }, Some(count) => { map.insert(num, count + 1); } } } // Now that we have counted all of the elements // we can check if any have a count that is greater // than 1. for (num, count) in map { if count > 1 { return true; } } return false; } }
Solution 3
We can improve solution 2 by using the following observation: we actually do not need the full count of every element, just whether the element has a count greater than 1. A different way of phrasing it is that while we are iterating through the vector, we just need to know if the current element is one we have seen before or not, and not the exact count of how many times we have seen it.
We can use a HashSet to realize this. Unlike a HashMap, a HashSet stores a set of keys without associating
them with any values. Inserting an element into a HashSet as well as retrieving an element from it are both fast,
constant-time operations.
You can think of the HashSet<T> as similar to a HashMap<T, bool> that maps elements that exist in the set to true,
and does not contain any mappings for elements outside the set.
We can use HashSet to come up with the code below:
#![allow(unused)] fn main() { use std::collections::HashSet; fn contains_duplicate(numbers: Vec<i32>) -> bool { let mut set = HashSet::new(); for num in numbers { if set.contains(&num) { return true; } set.insert(num); } return false; } }
Comparing The Solutions
Performance (Analytical)
Solution 1’s performance depends on sorting. Most good sorting algorithms take O(n log(n)) steps to complete their sort,
where n is the size of the vector. The loop following the sort simply goes through the vector once from start to end, and thus
takes roughly n steps. So in total, this program needs roughly O(n log(n)) steps.
Solution 2 and Solution 3 on the other hand take O(n) steps: solution two contains two loops: the first one
goes over the vector and manipulates the HashMap. Inserting and retrieving elements from a HashMap can each be done
in constant time (i.e., roughly one step), thus this loop has roughly O(n) steps. The second loop is also similar.
Solution 3 contains just one simple loop with n steps, since inserting and retrieving elements from a HashSet is also constant time (~ one step).
So, analytically, solution 1 takes O(n log(n)) while solutions 2 and 3 take O(n). So it appears that solutions
2 and 3 are equivalent and solution 1 is slowed.
Performance (Empirical)
The code we provide on GitHub benchmarks the solutions to see how long they take to execute with a vector with 10,000,000 elements and no duplicates. Surprisingly, we find that solution 1 is a little faster than solution 3, and much faster than solution 2. How come?
While the analytical analysis we did above with the big O notation is often very helpful, it is a rough analysis and skips over important details. Specifically, it glosses over what the “steps” actually entail and treats them as the same.
Sorting entails performing a bunch of comparisons (i.e. <) and swaps. These are really fast and simple operations
that a computer can execute blazingly quickly. Inserting into a HashMap is more complicated: it involves allocating
memory, freeing memory, and hashing keys behind the scenes. While that is constant time (i.e., a fixed number of steps
that does not depend on the size of the map), it is more complicated than a single <.
Furthermore, log(n) is actually quite a small quantity: for n = 10,000,000, log_2(n) is roughly 23. While a factor of 23
can be significant, the simplicity of the operations associated with it in solution 1 still wins over solution 2.
With that said, if n gets big enough, solution 2 will eventually win out, as the log(n) factor grows and eventually over
takes the complexity of the operations.
Solution 3 and Solution 1 are much closer in terms of runtime. Solution 3 can be optimized a little further
by issuing only one HashSet operation: it turns out insert returns whether the element is new or not, and so
we can use that and skip the contains() call.
Furthermore, Solution 3 has a subtle performance advantage: it will stop as soon as it detects a duplicate. imagine if the input vector is very large, but starts with two duplicates immediately. Solution 3 will detect that after two iterations and immediately return, while solutions 1 and 2 will need to complete sorting the entire vector and counting all of its elements, respectively, before getting to detecting the duplicates.
So, which of these solutions is actually faster? Well, that depends on the parameters of the problem:
- How big is the vector? If the vector is incredibly large, solution 1 will eventually become slower, but otherwise, it is faster than solution 2.
- Do we expect to have a lot of duplicates in our inputs? If so, solution 3 will be faster as it can stop as soon as it detects a duplicate!
- Are our input vectors small or medium in size (e.g. millions of elements)? Do they have no or few duplicates? Then, Solution 1 is probably fastest.
Readability, Ease of Development and Maintenance
Which of these programs is simplest to understand? Solution 1 and 3 are both much shorter, so it is easier to understand what they do. However, To understand why solution 1 works, you need to understand how sorting affects duplicates and make them appear in consecutive locations.
What about scenarios where the problem is changed slightly? Say, we want to instead find if an element appears 3 times or more, rather than just duplicates (count of 2)? Solution 3 will no longer, as it does not have the ability to track how many times an element appears. Solution 1 could still work, but now, it will need to check whether any 3 consecutive elements are the same. For example, by changing the loop to:
for i in 0..numbers.len() - 2 {
if numbers[i] == numbers[i+1] && numbers[i+1] == numbers[i+2] {
return true;
}
}What if we need to find if an element appears 100 times? It is still possible to do that with solution 1, but it can get really hairy: you either need to copy that condition above over 100 times, or use a nested loop to check each 100 elements. This also makes it much slower!
On the other hand, solution 2 is really easy to update to match these new requirements. You can simply change one line in its last loop as follows:
for (num, count) in map {
if count > 100 {
return true;
}
}We will see another example of this below.
Example 2 - Majority Element
Let’s move on to the majority element problem, which you also had to solve in homework 2.
In this problem, we are given a vector with n elements, and we need to return its majority element.
The majority element is the element who appears more than half the times in the vector.
For example, [1, 2, 3, 1, 1, 1] has majority element 1, and [1, 3, 3, 2, 3] has majority element 3.
By definition, the majority element has to appear more than n/2 times.
On the other hand, vector [1, 2, 1, 3, 1, 2] does not have a majority element. Sure, 1 is the most common
element in it, but it is not the majority as it appears exactly n/2 times, not greater than n/2 times.
The problem states that you can assume that a majority element exists in every vector you are given.
You can find our solutions here.
Solution 1
We can adapt solution 2 from contains duplicate above, which highlights how flexible that approach is.
#![allow(unused)] fn main() { use std::collections::HashMap; fn majority_element(numbers: Vec<i32>) -> i32 { let n = numbers.len(); // Construct a map from element to its count let mut map = HashMap::new(); for num in numbers { let value_in_map = map.get(&num); match value_in_map { None => { map.insert(num, 1); }, Some(count) => { map.insert(num, count + 1); } } } // Now that we have counted all of the elements // we can check if any have a count that is greater // than 1. for (num, count) in map { if count > n / 2 { return num; } } panic!("no majority element"); } }
Notice how we only needed to change a couple of lines!
Solution 2
A different approach is to rely on sorting. If a majority element exists (which the problem says we can assume), and we sort the vector, then the majority will be guaranteed to appear at the mid point of the vector.
For example, if you sort [1, 2, 3, 1, 1, 1], you will get [1, 1, 1, *1*, 2, 3].
Similarly, if you sort [1, 3, 3, 2, 3], you will get [1, 2, *3*, 3, 3]. We highlight the middle
element (i.e. the element at index n/2) using stars.
Notice that in both cases, the middle element was the majority element.
With some more thinking, you can even mathematically prove this: the majority element appears more than n/2 times. When you sort the vector, all these occurrences appear consecutively. So they must occupy a contiguous chunk of size greater than n/2. There is no way to fit n/2 contiguous elements in a vector of size n without spilling over the mid point!
We can code this solution as follows:
#![allow(unused)] fn main() { fn majority_element(mut numbers: Vec<i32>) -> i32 { numbers.sort(); return numbers[numbers.len() / 2]; } }
Solution 3
Finally, we consider a radically different solution. The majority element is, by definition, very common. So, if we pick a random element, chances are, that element is the majority element.
So, we can pick a random element, check if it is the majority element, return it if it is, and otherwise, repeat the process with a new random element, and so on.
The odds of us getting unlucky and not choosing the majority element after k tries become increasingly smaller
and smaller as we make more tries.
In fact, you can even prove that the probability of getting unlucky after k tries is at most 0.5^k, since
the probability of selecting the majority element at any step is at least 0.5.
To give you a sense of how this probability grows, when k = 1, the probability is less than 1/2. For k = 3, the probability is less than 1/8. For k = 10, the probability is less than 0.001. For k = 100, the probability is so so tiny that I would bet my arm, leg, and favorite guitar against it happening.
We can code this solution up as follows:
fn majority_element(numbers: &Vec<i32>) -> &i32 {
loop {
// println!("Guessing again");
let random_number = helpers::random_element(v);
let mut count_of_random_number = 0;
for i in numbers {
if random_number == i {
count_of_random_number += 1;
}
}
if count_of_random_number > numbers.len() / 2 {
return random_number;
}
}
}Comparing Solutions
Performance
Solution 1 and 2 take O(n) and O(n log(n)) steps, for similar reasons to example 1. Solution 3
takes roughly O(k * n) where k is the number of guesses taken until the majority element is found.
Realistically, k will be quite small (around ~2 on average), and importantly, it does not depend
on how large the vector is.
Run the provide code using these commands and see which are solutions are fastest and by how much
cargo run --bin sol1 --release
cargo run --bin sol2 --release
cargo run --bin sol3 --release
Readability and Understandability
Which of these solutions is easiest to understand? Both in terms of what the code does, and in terms of why it works.
Imagine, you were not provided with the explanation about why sorting results in the majority element showing up in the mid point, or the explanation about the probability of finding the majority element by guessing randomly. Would it be difficult for you to understand these concepts on your own?
Ease of Maintenance
Imagine that the problem was updated in the future so that you cannot assume that the majority element exist.
Instead, that you must return a special value, e.g., -1 or None, when a majority element does not exist (or produce an error).
How easy is it to modify each of these solutions to do that?
What if the problem is changes to finding the most common element, even if it is not the majority element?
Consider these metrics and pick your favorite solution. As with most things that have to do with taste, this is subjective and there might be many acceptable answers, but you have to be ready to provide your justifications for why that is the case!
Structs and Enums
Lecture 5: Wednesday, May 27, 2026
Code examples
So far, the types we have worked with (numbers, strings, vectors, hash maps) are all built into Rust. But real programs deal with data that doesn’t fit neatly into any single built-in type. In this module, we will learn about two tools for defining our own types in Rust:
- structs, which group related data together, and
- enums, which describe data that can take one of several distinct forms.
We will learn both through a running example: a simple bank account.
Starting Simple: Just Variables
A bank account needs to track two things: the current balance, and a history of all past transactions. Let’s start with the most straightforward approach: two variables.
For now, we’ll represent transactions as integers: positive values for deposits, negative values for withdrawals.
fn main() { let mut balance: i32 = 0; let mut transactions: Vec<i32> = vec![]; // I deposited $100 balance += 100; transactions.push(100); // I withdrew $20 balance -= 20; transactions.push(-20); // I withdrew another $30 balance -= 30; transactions.push(-30); // What's my current balance? println!("Balance: {balance}"); // How many withdrawals have I made? let mut count = 0; for transaction in transactions { if transaction < 0 { count += 1; } } println!("Withdrawals: {count}"); }
This works! But there are several serious problems lurking here.
Think about what could go wrong with this code before reading on.
Problem 1: The data can fall out of sync.
balance and transactions are related: the balance is the sum of all the transactions.
But they live as two completely separate variables.
Nothing in the code forces us to update both together.
If we accidentally forget to push to transactions after updating balance (or vice versa),
the two will silently disagree.
Rust will not warn us.
Problem 2: The convention is invisible.
Our rule that “negative = withdrawal, positive = deposit” exists only in our minds.
Nothing about the type Vec<i32> encodes this meaning.
Another programmer (or a future you, a week from now) might accidentally push 20 instead of -20 for a withdrawal.
The data would be silently wrong.
Problem 3: Multiple accounts are a mess.
What if we need to track two bank accounts? We’d need two balance variables and two transactions vectors, with no automatic link between the balance for account A and the transactions for account A. It gets unwieldy fast.
Problem 4: Logic is scattered everywhere.
The “count withdrawals” code lives inside main. If we need that logic in several places in a larger codebase, we have to copy it each time, and remember to update every copy whenever the logic changes.
Grouping Data with a Struct
The first tool we need is a struct. A struct lets us define a new named type by listing the pieces of data it contains, called fields.
Here is the syntax:
struct BankAccount { pub balance: i32, pub transactions: Vec<i32>, }
This tells Rust: “a BankAccount is made up of an i32 field called balance, and a Vec<i32> field called transactions.” The pub keyword means the fields are public. They are visible and accessible from outside the struct (more on this shortly).
To create a BankAccount, we use struct literal syntax, listing the initial value for each field:
struct BankAccount { pub balance: i32, pub transactions: Vec<i32>, } fn main() { let mut account = BankAccount { balance: 0, transactions: vec![], }; // I deposited $100 account.balance += 100; account.transactions.push(100); // I withdrew $20 account.balance -= 20; account.transactions.push(-20); // I withdrew another $30 account.balance -= 30; account.transactions.push(-30); println!("Balance: {}", account.balance); let mut count = 0; for transaction in account.transactions { if transaction < 0 { count += 1; } } println!("Withdrawals: {count}"); }
We access a struct’s fields using dot notation: account.balance, account.transactions.
This is already a meaningful improvement.
balance and transactions are now grouped under a single account variable.
They travel together throughout our code.
If we need a second account, we simply create a second BankAccount, without juggling extra variables.
But we haven’t solved all our problems:
- The fields are
pub, so any code anywhere can freely read or modifyaccount.balanceandaccount.transactionsdirectly, nothing enforces that they stay consistent. - The convention that withdrawals are negative is still only in our minds.
- The “count withdrawals” logic is still copy-pasted in
main.
Encapsulation
The idea of encapsulation is to go one step further: not just group the data together, but also control how the data can be accessed or modified.
Instead of letting the outside world poke at balance and transactions directly, we hide those fields and expose only the operations we want to allow. For example, making a deposit or printing the balance.
Modules
Before we can hide fields, we need to understand Rust modules.
In Rust, accessibility of some field or function is scoped to a module.
A module is a named unit of code, like a file or a namespace.
Code inside a module can access all the private items within that same module.
Code outside the module can only use items marked with pub.
This matters here: if everything lives in main.rs, there is only one module (the entire program), and nothing is truly encapsulated from main.
To get real encapsulation, we need to put BankAccount in its own module.
The most common way to do this in Rust is to create a separate file. We create src/types.rs for our types, and declare it in main.rs with mod types;:
// src/main.rs
mod types; // tells Rust: find types.rs and treat it as a submodule
use types::BankAccount; // bring BankAccount into scope// src/types.rs
pub struct BankAccount {
// ...
}The pub on the struct itself means the type is visible outside the module. Without it, even the name BankAccount would be hidden.
Modules are also useful beyond just encapsulation: in a larger project, splitting code across multiple files keeps each file focused and manageable. You might have one module for data types, another for I/O, another for algorithms. We will see more of this as the course progresses.
You can also define a module inline, using mod types { ... } directly in the same file. Both forms create the same module, they just differ in where the code lives.
Since the playground in these lecture notes doesn’t support multiple files, we’ll use the inline form in all the examples below:
mod types { pub struct BankAccount { // fields go here } } use types::BankAccount; // bring BankAccount into scope
Private Fields, Methods, and Constructors
Now let’s make the fields private by removing pub from them:
mod types { pub struct BankAccount { balance: i32, // private: no pub transactions: Vec<i32>, // private: no pub } }
As soon as we do this, a new problem appears. The struct literal syntax we used earlier requires naming each field. But since balance and transactions are now private, code outside mod types can no longer name them directly:
mod types { pub struct BankAccount { balance: i32, transactions: Vec<i32>, } } use types::BankAccount; fn main() { let account = BankAccount { balance: 0, transactions: vec![] }; }
error[E0451]: fields `balance` and `transactions` of struct `BankAccount` are private
--> src/main.rs:11:33
|
11 | let account = BankAccount { balance: 0, transactions: vec![] };
| ^^^^^^^ ^^^^^^^^^^^^ private field
| |
| private field
With private fields, we can no longer construct a BankAccount using struct literal syntax from outside the module. We need a constructor: a pub function that creates and returns a new BankAccount. By convention in Rust, this function is called new.
mod types { pub struct BankAccount { balance: i32, transactions: Vec<i32>, } impl BankAccount { pub fn new() -> BankAccount { return BankAccount { balance: 0, transactions: vec![], }; } } }
The impl BankAccount { ... } block is how we define methods: functions that belong to a type.
Inside new, we can access the private fields because we are inside the types module. Code outside cannot.
The -> BankAccount return type should look familiar from module 5: new takes no arguments and returns a freshly constructed BankAccount.
Now let’s add the rest of the methods, and put them all together with a main to try them out:
mod types { pub struct BankAccount { balance: i32, transactions: Vec<i32>, } impl BankAccount { pub fn new() -> BankAccount { return BankAccount { balance: 0, transactions: vec![], }; } pub fn deposit(&mut self, amount: i32) { self.balance += amount; self.transactions.push(amount); } pub fn withdraw(&mut self, amount: i32) { if amount > self.balance { panic!("not enough funds!"); } self.balance -= amount; self.transactions.push(-amount); } pub fn print_balance(&self) { println!("{}", self.balance); } pub fn count_withdrawals(self) { let mut count = 0; for transaction in self.transactions { if transaction < 0 { count += 1; } } println!("{count}"); } } } use types::BankAccount; fn main() { let mut account = BankAccount::new(); account.deposit(100); account.withdraw(20); account.withdraw(30); account.print_balance(); account.count_withdrawals(); }
Notice that each method has a special first parameter involving self. Think of it as the current BankAccount the method was called on. When you write account.deposit(100), the value of account is what becomes self inside deposit, which is how self.balance += amount updates that account’s balance specifically.
The & and &mut in front of self are part of Rust’s reference system, which we will cover in detail in the next module. For now, just note that methods use &self when they only read data, &mut self when they also need to modify it, and no self at all (like new) when they create a new instance from scratch.
What do you think happens if you try to write
account.balancedirectly inmaininstead of callingaccount.print_balance()?
You get a compile error:
mod types { pub struct BankAccount { balance: i32, transactions: Vec<i32>, } impl BankAccount { pub fn new() -> BankAccount { return BankAccount { balance: 0, transactions: vec![] }; } } } use types::BankAccount; fn main() { let account = BankAccount::new(); println!("{}", account.balance); }
error[E0616]: field `balance` of struct `BankAccount` is private
--> src/main.rs:18:28
|
18 | println!("{}", account.balance);
| ^^^^^^^ private field
The only way to interact with a BankAccount from outside mod types is through the pub methods we explicitly provided. Everything else is locked out at compile time.
Enforcing Invariants in One Place
One of the most important benefits of encapsulation is the ability to enforce invariant rules that should always hold true for our data.
For a bank account, one obvious invariant is: the balance should never go negative. Let’s see what happens without encapsulation.
With public fields, a withdrawal anywhere in the code might look like:
account.balance -= 20;
account.transactions.push(-20);To enforce the invariant, you’d need to add a check every single time a withdrawal is made, in every part of the codebase:
if 20 > account.balance {
panic!("Not enough funds!");
}
account.balance -= 20;
account.transactions.push(-20);Miss that check in even one place and the invariant is silently violated.
With our private fields and withdraw method, there is exactly one place in the entire program where a withdrawal can happen:
pub fn withdraw(&mut self, amount: i32) {
if amount > self.balance {
panic!("not enough funds!");
}
self.balance -= amount;
self.transactions.push(-amount);
}No matter how many places in main call account.withdraw(...), this check will always run. It is impossible to bypass it.
Enums: Richer Transactions
Our Vec<i32> representation still has a subtle weakness. Inside count_withdrawals, we check if transaction < 0 to detect a withdrawal. This relies on a sign convention that lives only in our minds, not in the types of the program.
Rust doesn’t know anything about this convention; it just sees integers.
And if we someday needed a third kind of transaction (a bank fee, a refund) we’d have to invent yet another numeric convention and add more if checks everywhere.
Rust’s enums let us do better. An enum defines a type that can be exactly one of several named variants. We have already seen Option<T>, which is a built-in enum with two variants: None and Some(T). Now let’s define our own.
pub enum Transaction { Deposit(i32), Withdrawal(i32), }
This says: “A Transaction is either a Deposit carrying an i32, or a Withdrawal carrying an i32.” The i32 in each variant represents the raw change to the balance: positive for a deposit, negative for a withdrawal.
Now we can replace Vec<i32> with Vec<Transaction> in BankAccount. Instead of separate deposit and withdraw methods, we can unify them into a single make_transaction method that takes a Transaction:
mod types { pub enum Transaction { Deposit(i32), Withdrawal(i32), } pub struct BankAccount { balance: i32, transactions: Vec<Transaction>, } impl BankAccount { pub fn new() -> BankAccount { return BankAccount { balance: 0, transactions: vec![], }; } pub fn make_transaction(&mut self, transaction: Transaction) { match transaction { Transaction::Deposit(amount) => { self.balance += amount; } Transaction::Withdrawal(amount) => { if amount * -1 > self.balance { panic!("not enough funds!"); } self.balance += amount; } } self.transactions.push(transaction); } pub fn print_balance(&self) { println!("{}", self.balance); } pub fn count_withdrawals(self) { let mut count = 0; for transaction in self.transactions { match transaction { Transaction::Deposit(_) => {} Transaction::Withdrawal(_) => { count = count + 1; } } } println!("{count}"); } } } use types::BankAccount; use types::Transaction; fn main() { let mut account = BankAccount::new(); account.make_transaction(Transaction::Deposit(100)); account.make_transaction(Transaction::Withdrawal(-20)); account.make_transaction(Transaction::Withdrawal(-30)); account.print_balance(); account.count_withdrawals(); let new_account = BankAccount::new(); new_account.count_withdrawals(); }
Let’s look at what’s better about this.
The type tells you everything. A Transaction::Withdrawal is unmistakably a withdrawal. No conventions to remember, no comments needed. The name is part of the value.
match is exhaustive. Recall from module 5 how Rust forces you to handle all cases in a match. That same rule applies to our enum. If we add a new variant (Fee(i32) for bank fees), every match on a Transaction in the whole codebase will produce a compile error until we handle the new case. The compiler tells us exactly where to go update the code. No missing cases, no surprises.
For example, if we added Fee(i32) to the enum but forgot to handle it in count_withdrawals, Rust would say:
error[E0004]: non-exhaustive patterns: `Transaction::Fee(_)` not covered
| match transaction {
| ^^^^^^^^^^^ pattern `Transaction::Fee(_)` not covered
The invariant check is still in one place. make_transaction handles both kinds of transactions, and the overdraft check lives there.
You can find the complete code here.
Module 8: Parameter Passing
Lecture 6: Thursday, May 28, 2026.
Code examples
In this module, we will learn about:
- How data can be passed to a function as a parameter: by clone, by const reference, by mutable reference, and by move.
- The benefits and disadvantages of each way of passing a parameter, and when to use each.
Forward on References
A reference is a way to refer to a value without taking ownership of it. References come in two flavors:
- Const reference (
&T): read-only access to the referenced value. - Mutable reference (
&mut T): read and write access to the referenced value.
To create a reference to a value, we use the & operator — this is called borrowing. For a mutable reference, we use &mut. Notice in the example below that mutating through ref2_x1 also changes x1, since they both refer to the same value.
fn main() { let mut x1: i32 = 10; // This is a const ref. let ref_x1: &i32 = &x1; println!("ref_x1 refers to value {}", ref_x1); // This is a mut ref. let ref2_x1: &mut i32 = &mut x1; *ref2_x1 += 1; println!("ref2_x1 refers to value {}", ref2_x1); println!("x1 also changed {}", x1); }
Rust enforces important rules about references at compile time. These ensure that references always refer to something, and that at most one reference can mutate the underlying data at any given time. We will look at these rules in depth later in the course.
Passing Data to Functions
One of the most common uses of references is passing data to functions. There are four main ways to pass data.
Pass by Const Reference
Passing a const reference (&T) is very fast and gives the function read-only access to the data.
fn midpoint(v: &Vec<i32>) -> usize { return v.len() / 2; } use std::time::{Instant}; fn main() { // Make a big vector with 1,000,000 elements. let mut my_vec = Vec::with_capacity(1000000); for i in 0..1000000 { my_vec.push(i); } let time = Instant::now(); let mid = midpoint(&my_vec); // pass by const ref println!("Took {:?}", time.elapsed()); println!("Mid point element is {}", my_vec[mid]); }
Pass by Clone
Passing by clone creates an independent copy of the data for the function. Compare how long this takes versus passing by reference:
fn midpoint2(v: Vec<i32>) -> usize { return v.len() / 2; } use std::time::{Instant}; fn main() { // Make a big vector with 1,000,000 elements. let mut my_vec = Vec::with_capacity(1000000); for i in 0..1000000 { my_vec.push(i); } let time = Instant::now(); let mid = midpoint2(my_vec.clone()); // pass by clone println!("Took {:?}", time.elapsed()); println!("Mid point element is {}", my_vec[mid]); }
Passing by clone is much slower than passing by reference, because clone() copies all elements of the vector into a brand new vector before passing it to the function.
Pass by Move
Passing by move transfers ownership of the data to the function. Try to compile the following code:
fn midpoint3(v: Vec<i32>) -> usize { return v.len() / 2; } use std::time::{Instant}; fn main() { // Make a big vector with 1,000,000 elements. let mut my_vec = Vec::with_capacity(1000000); for i in 0..1000000 { my_vec.push(i); } let time = Instant::now(); let mid = midpoint3(my_vec); // pass by move println!("Took {:?}", time.elapsed()); println!("Mid point element is {}", my_vec[mid]); }
The compiler will produce an error: my_vec can no longer be used after being moved into midpoint3. Once data is moved into a function, the caller loses access to it. We will study why this is the case at a deeper level in a later lecture.
We can fix the error by not using my_vec after the move:
fn midpoint3(v: Vec<i32>) -> i32 { let mid = v[v.len() / 2]; return mid; } use std::time::{Instant}; fn main() { // Make a big vector with 1,000,000 elements. let mut my_vec = Vec::with_capacity(1000000); for i in 0..1000000 { my_vec.push(i); } let time = Instant::now(); let mid = midpoint3(my_vec); // pass by move println!("Took {:?}", time.elapsed()); println!("Mid point element is {}", mid); }
Pass by Mutable Reference
Passing a mutable reference (&mut T) is also very fast and gives the function both read and write access to the original data. Any changes the function makes will be visible in the caller.
fn add_0_to_vec(v: &mut Vec<i32>) { v.push(0); } fn main() { let mut v: Vec<i32> = Vec::new(); add_0_to_vec(&mut v); // pass by mut ref println!("{:?}", v); }
Experiment with the above code. What happens if v were immutable (e.g., let v: Vec<i32> = Vec::new())?
Advantages and Disadvantages
We have the following ways to pass data to a function:
- Pass by clone:
- pros: gives the function a separate copy of the data it can control and modify without affecting the original data.
- cons: slow and uses extra memory.
- Pass by const reference:
- pros: very fast, the owner of the data can relax knowing their data is not going to be modified.
- cons: the function cannot modify the data.
- Pass by mutable reference:
- pros: very fast; the function can modify the data.
- cons: changes made by the function will affect the original variable in the caller.
- Pass by move:
- pros: very fast and gives the function full ownership of the data.
- cons: the original variable can no longer be used in the caller after the move.
Remember these pros and cons! We may ask you about them in the midterm :)
When Should You Use Each Of These?
Consider the following exercise questions:
- If you are asked to build a function that prints a given vector, would you choose to pass the vector by clone, const ref, mut ref, or move? Why?
- If you are asked to build a function that removes all even numbers from a vector, how would you pass the vector and why?
- If you are asked to build a function that creates a sorted copy of a vector while keeping the original vector unchanged, how would you pass the vector? Why?
Module 9: Generics, Traits, and Derive
Lecture 6: Thursday, May 28, 2026,
Lecture 7: Tuesday, June 2, 2026.
Code examples
In this module, we will learn about:
- How we can use generics to reduce code duplication.
- How to define shared behavior among many types using traits.
- How to combine traits and generics using trait bounds to write general reusable code!
- Learn about popular builtin traits and how we can implement them for our types using derive.
Example Scenario: Library
Let’s start with the following example that we will re-use throughout these notes. In this scenario, we are a public library that users check out books from.
Our starting point is defining what a book is. This is a new type! We can use struct to define it.
In this scenario, let’s say a book is made out of a title and an author name, both strings, and an ISBN and an edition
number, both integers.
#![allow(unused)] fn main() { pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } }
In this case, we can represent our library’s stock as a vector containing many books, perhaps including several copies of the same book! As an example, let’s say our library contains three copies of various editions of the first Harry Potter book, and one copy of the Art of Computer Programming.
let library_books: Vec<Book> = vec![
Book {
title: String::from("Harry Potter and The Philosopher's Stone"),
author: String::from("JK Rowling"),
isbn: 10,
edition: 1,
},
Book {
title: String::from("Harry Potter and The Philosopher's Stone"),
author: String::from("JK Rowling"),
isbn: 10,
edition: 1,
},
Book {
title: String::from("Harry Potter and The Philosopher's Stone"),
author: String::from("JK Rowling"),
isbn: 10,
edition: 2,
},
Book {
title: String::from("The Art of Computer Programming"),
author: String::from("Donald Knuth"),
isbn: 33,
edition: 1,
},
];Now, say a user walks into our library looking for some book, say the first Harry Potter book, and wanting to borrow it. We will need to check our stock to find out whether we have any available copies of that book. Let’s build a function that does that.
// `book` is the book the user is looking for.
// `library_books` is the vector of books we have available.
// the function should return how many matching copies we have in our library.
fn available_copies(book: &Book, library_books: &Vec<Book>) -> u64 {
let mut count = 0;
for b in library_books {
// check if `b`, the book we are currently looking at, matches
// the requested book.
if b.title == book.title
&& b.author == book.author
&& b.isbn == book.isbn
&& b.edition == book.edition {
count += 1;
}
}
return count;
}Let’s put all this together and test our code. Run the code below and observe its output!
pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } // `book` is the book the user is looking for. // `library_books` is the vector of books we have available. // the function should return how many matching copies we have in our library. fn available_copies(book: &Book, library_books: &Vec<Book>) -> u64 { let mut count = 0; for b in library_books { // check if `b`, the book we are currently looking at, matches // the requested book. if b.title == book.title && b.author == book.author && b.isbn == book.isbn && b.edition == book.edition { count += 1; } } return count; } fn main() { let library_books: Vec<Book> = vec![ Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 2, }, Book { title: String::from("The Art of Computer Programming"), author: String::from("Donald Knuth"), isbn: 33, edition: 1, }, ]; let target_book = Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1 }; let count = available_copies(&target_book, &library_books); println!("The library has {} copies", count); }
Our First Trait: PartialEq
One downside of our code is how we implemented equality checking between books (the if statement inside available_copies).
The check is too verbose: it compares every field inside the two books to each other. This is not ideal: imagine if the
programmers had to change the Book type, by adding or removing some fields from it (e.g., to support having multiple authors for one book).
The programmers would then need to remember to change the code inside available_copies to match their changes to Book.
It also looks unnatural.
Perhaps a better approach is to replace that if statement with something more natural. For example, if b == book { ... }!
Modify the code above to use a direct equality check, run it, and look at the output!
You will find that Rust gives the following compile-time error:
error[E0369]: binary operation `==` cannot be applied to type `&Book`
--> src/main.rs:16:10
|
16 | if b == book {
| - ^^ ---- &Book
| |
| &Book
|
note: an implementation of `PartialEq` might be missing for `Book`
--> src/main.rs:1:1
Rust essentially complains about the equality check with ==. Specifically, Rust tells us that it does not
know what equality means for books: we defined the type Book ourselves, but did not tell Rust how to compare two books!
A good start would be to implement our own equality check function for Book. For example:
impl Book {
pub fn check_equals(&self, other_book: &Book) -> bool {
return self.title == other_book.title
&& self.author == other_book.author
&& self.isbn == other_book.isbn
&& self.edition == other_book.edition;
}
}Now, we can call this function to check if two books are equal, e.g., using if b.check_equals(book) { ... }.
Here’s the complete code below, run it and observe the output!
pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } impl Book { pub fn check_equals(&self, other_book: &Book) -> bool { return self.title == other_book.title && self.author == other_book.author && self.isbn == other_book.isbn && self.edition == other_book.edition; } } // `book` is the book the user is looking for. // `library_books` is the vector of books we have available. // the function should return how many matching copies we have in our library. fn available_copies(book: &Book, library_books: &Vec<Book>) -> u64 { let mut count = 0; for b in library_books { // check if `b`, the book we are currently looking at, matches // the requested book. if b.check_equals(book) { count += 1; } } return count; } fn main() { let library_books: Vec<Book> = vec![ Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 2, }, Book { title: String::from("The Art of Computer Programming"), author: String::from("Donald Knuth"), isbn: 33, edition: 1, }, ]; let target_book = Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1 }; let count = available_copies(&target_book, &library_books); println!("The library has {} copies", count); }
This is better, but it is explicitly calling check_equals. It is more natural to use ==. Modify the above code to use == and try to run it again.
error[E0369]: binary operation `==` cannot be applied to type `&Book`
--> src/main.rs:26:10
|
26 | if b == book {
| - ^^ ---- &Book
| |
| &Book
|
note: an implementation of `PartialEq` might be missing for `Book`
--> src/main.rs:1:1
The same error!
Rust is unaware that check_equals correspond to ==. Why would it?! Rust does not understand English, and has no way
of knowing that we intended for check_equals to define how to do ==.
How can we inform Rust of this intention? We can using traits!
Specifically, Rust provides a “trait” called PartialEq, which corresponds to the == operation. We can implement it for Book instead.
impl PartialEq for Book {
fn eq(&self, other_book: &Book) -> bool {
return self.title == other_book.title
&& self.author == other_book.author
&& self.isbn == other_book.isbn
&& self.edition == other_book.edition;
}
}We highlight the following observations:
- The syntax for implementing a trait is
impl <trait name> for <type name>. - Inside the
implblock, you need to provide an implementation for every function that the trait defines.
Specifically, if you make a typo in the name of the function (say equals instead of eq), or if you mess up the
signature, the compiler will give you an error.
Now, we can put all this together. Look at what the if condition now checks in available_copies. Run the code to confirm it works.
pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } impl PartialEq for Book { fn eq(&self, other_book: &Book) -> bool { return self.title == other_book.title && self.author == other_book.author && self.isbn == other_book.isbn && self.edition == other_book.edition; } } // `book` is the book the user is looking for. // `library_books` is the vector of books we have available. // the function should return how many matching copies we have in our library. fn available_copies(book: &Book, library_books: &Vec<Book>) -> u64 { let mut count = 0; for b in library_books { if b == book { count += 1; } } return count; } fn main() { let library_books: Vec<Book> = vec![ Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 2, }, Book { title: String::from("The Art of Computer Programming"), author: String::from("Donald Knuth"), isbn: 33, edition: 1, }, ]; let target_book = Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1 }; let count = available_copies(&target_book, &library_books); println!("The library has {} copies", count); }
Traits
Traits are Rust’s way of defining a contract. Think of it as Rust’s way of declaring that some types implement certain behavior.
For example, the PartialEq trait defines a contract for equality checking. Specifically, instances of any type that implements PartialEq
can be compared against each other using ==. Another example is the Clone trait: instances of types that implement Clone can be cloned using .clone()!
Thinking about traits involves two facets:
- What is the trait definition or contract?
- What types implement this trait (and how)?
Let’s start by looking at the definition of PartialEq. We put a simplified version of its implementation
below. If you are curious, you can look at its docs for more details.
#![allow(unused)] fn main() { pub trait PartialEq { // Required method that we must implement for our types // when we implement PartialEq for them. // Self: our type that we are implementing the trait for (for example, Book). fn eq(&self, other: &Self) -> bool; } }
We highlight the following:
- We define a trait using the
traitkeyword and then giving the trait a name, similar to howstructorfnworks. - Inside the trait, we can define one or more function signatures. These are the behaviors required by the trait contract.
- Every type that implements this trait must implement all these functions.
- The trait itself does not specify how these functions are implemented – notice how they have no bodies!
- Instead, when we implement a trait for some type, that’s when we have to provide the function body and implementation.
You can read more about traits in the Rust book.
Other Builtin Traits
In addition to PartialEq, Rust has a number of other commonly used builtin traits:
- Clone: indicates that instances of a type can be cloned.
- Debug: indicates that instances of a type can be printed using
println!("{:?}", <instance>);. - Display: indicates that instances of a type can be printed using
println!("{}", <instance>);. - PartialOrd: indicates that instances of a type can be compared to each other using
<,>, etc.
Furthermore, there are several common and widely used traits that are provided by common libraries in Rust. We have seen some of them already in project 3!
- Serialize: indicates that instances of a type can be serialized, i.e., transformed to binary or to JSON.
- Deserialize: indicates that instances of a type can be deserialized, i.e., retrieved from binary or from JSON.
Derive
When we define a custom type, like Book, it is common to implement many of these traits for that type (when they make sense).
In many cases, this implementation is not interesting: to implement PartialEq, we frequently simply want to compare all matching fields from two objects.
When implementing Clone, we often simply want to clone every field.
In these cases, Rust allows us to use derive to automatically implement these traits for our types, without writing out all the code and implementation.
For example, instead of impl PartialEq for Book {...} block, we can instead just write the following:
#![allow(unused)] fn main() { #[derive(PartialEq)] pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } }
You can derive more than one trait by separating them with a comma. For example #[derive(PartialEq, Clone)].
Exercise: modify the scenario code above to use derive instead of manual implementation of the trait. Run the code to confirm it works.
When should you use derive?
Use derive for builtin or external traits where you want to implement them the “default” way, as in, by applying the trait to a type’s fields or components.
When should you not use derive?
derive is not available for all traits. If you define your own custom trait, it will not be derivable by default. You will need to implement your own
derive macro for it to enable automatic deriving.
Furthermore, even if a trait support derive, you may still want to manually implement it if you want to specify custom, non-default logic for how to implement
its behavior.
For example, the default PartialEq implementation compares all the fields in the two objects to each other. However, let’s say that we want to consider books with the same
ISBN to be equal regardless of edition. This way, if the only available copy of the Harry Potter book has edition 2, the user can still find it and check it out!
// This is a non-default implementation of PartialEq.
// If this is our goal, then we cannot use derive.
impl PartialEq for Book {
fn eq(&self, other_book: &Book) -> bool {
return self.isbn == other_book.isbn;
}
}Exercise: modify the scenario code above to compare books based on ISBN only. Run the code. How many available copies of the first Harry Potter book get identified after your modification?
Using Generics to Avoid Code Duplication
Our available_copies function seems like a helpful and reusable helper function: it counts how many matching elements a vector contains. You could
imagine using it for all sorts of examples, not just a library with books! However, the way we implemented this function is very specific:
it only works for a Book and a vector of Books. It would not work for, for example, a String with a vector of Strings!
Let’s see if we can change that using generics. Rather than defining this function for the specific Book type (this is often called a concrete type),
we can define it for a generic/general type T as follows:
#![allow(unused)] fn main() { fn count_occurrences<T>(element: &T, vector: &Vec<T>) -> u64 { todo!() } }
Let’s dig deeper into this function signature:
- Notice that we renamed the function and parameters name to something more general:
- Instead of calling the function
available_copies, which is highly specific to the library example, we called itcount_occurrences. This expresses the same behavior but in a more general way! - Similarly, instead of calling the parameters
bookandlibrary_books, we renamed them toelementandvector.
- Instead of calling the function
- After the function name, we added
<T>: this represents a type parameter. In some ways, it is similar to a regular parameter (e.g., element): it’s something that the caller of the function must provide. However, unlike a regular parameter that the caller provides a value for (e.g., a specific book or element), the caller must provide a type for the type parameter.- When reading the function signature, think of
Tas a generic unspecified type. It can take on any type the caller wants to. For example, it may becomeStringif the caller uses this function with strings, orBookif the caller uses books, etc.
- When reading the function signature, think of
- The type of the function parameters are different:
- The element (or book) used to be of type
&Book, now it is&T. - The vector used to be of type
&Vec<Book>, now it is&Vec<T>.
- The element (or book) used to be of type
Imagine what would happen if a caller sets T to be Book. If you plug Book in for T, the signature of the function collapses to the old one!
Functions can take more than one generic parameters. For example, we could have written the function as fn count_occurrences<T, F>(element: &T, vector: &Vec<F>) -> u64 { ... }. However, this allows the caller to provide different types for each type parameter. For example, they could set T to String and F to u32. This does not make a lot of sense for our particular use case, since we want the provided element to have the same type as the elements inside the vector.
OK, let’s go ahead and implement the body of the function:
#![allow(unused)] fn main() { fn count_occurrences<T>(element: &T, vector: &Vec<T>) -> u64 { let mut counter = 0; // e's type is &T for e in vector { if e == element { counter += 1; } } return counter; } }
Try to run this code. We will encounter a familiar compile-time error:
error[E0369]: binary operation `==` cannot be applied to type `&T`
--> src/main.rs:7:10
|
7 | if e == element {
| - ^^ ------- &T
| |
| &T
Rust is unsure of how to compare instances of T with each other. This makes sense! Remember how
previously, Rust was unsure how to compare instances of Book! We had to implement (or derive) PartialEq for Book to explain to Rust what equality checking for Book means.
We need to do something similar here. However, T is not a concrete or known type. We cannot
implement or derive any trait for T, because we do not even know what T is!
Trait Bounds
This is where trait bounds come in. We cannot implement anything for T, but we can pose a constraint about what types callers may plug in for that T. Specifically, we want to say that a caller can use any type they want for T, as long as that type implements PartialEq.
#![allow(unused)] fn main() { fn count_occurrences<T: PartialEq>(element: &T, vector: &Vec<T>) -> u64 { let mut counter = 0; // e's type is &T for e in vector { if e == element { counter += 1; } } return counter; } }
Now this code compiles, because we specific that T must implement PartialEq (and therefore has equality checking defined).
Trait bounds can get complex sometimes, e.g., if we need a type to implement several traits. For that, we can use the where syntax to make expressing these constraints easier. For example:
#![allow(unused)] fn main() { fn count_occurrences<T>(element: &T, vector: &Vec<T>) -> u64 // we could also use T: PartialEq + Clone where T: PartialEq, T: Clone { let mut counter = 0; // e's type is &T for e in vector { if e == element { counter += 1; } } return counter; } }
Putting this all together, we get the following code:
#[derive(PartialEq)] pub struct Book { pub title: String, pub author: String, pub isbn: u64, pub edition: u64, } // `book` is the book the user is looking for. // `library_books` is the vector of books we have available. // the function should return how many matching copies we have in our library. fn count_occurrences<T: PartialEq>(element: &T, vector: &Vec<T>) -> u64 { let mut count = 0; for e in vector { // check if `b`, the book we are currently looking at, matches // the requested book. if element == e { count += 1; } } return count; } fn main() { let library_books: Vec<Book> = vec![ Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1, }, Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 2, }, Book { title: String::from("The Art of Computer Programming"), author: String::from("Donald Knuth"), isbn: 33, edition: 1, }, ]; let target_book = Book { title: String::from("Harry Potter and The Philosopher's Stone"), author: String::from("JK Rowling"), isbn: 10, edition: 1 }; let count = count_occurrences(&target_book, &library_books); println!("The library has {} copies", count); }
Notice how we call the count_occurrences function in main. We do not need to explicitly provide
the types we want the generic type parameter T to become. Instead, Rust automatically deduces this from the type of target_book and library_books.
Exercise: Modify the code so that Book does not implement/derive PartialEq. Do you think that code should work? Run it and see if your intuition was correct! Try to understand the error message given what we discussed.
Exercises
Exercise 0: Reading and Quiz
Read chapters 10, 10.1, and 10.2 in the Rust book and answer the quiz at the end of 10.1 and 10.2!
After you answer all the questions in a quiz, you will see a report showing you which of your answers were correct and which were not. Use the rust playground to validate your answers and find out why you might have been incorrect!
Exercise 1: Derive
Create a new Rust project, open it with VSCode, and copy over the last complete code sample into your VSCode.
Let’s say our library also has magazines that users can borrow. A magazine has a name, a month, and a year. The name is a String, the month and year are integers.
- Define a type/struct to represent these magazines.
- Create a vector of magazines for representing what magazines your library has.
- Use
count_occurencesto count how many copies of a particular magazine the library has.
Note: the copy of the magazine must match all of the name, month, and year.
Exercise 2: Custom Trait
Now, define a new custom Trait, call it Checkout. This trait should define a function checkout, for checking out an item from the library.
Implement Checkout for both Book and Magazine. The implementation should print out the information of the item along with “checked out!”.
Hint: how should self be passed to checkout? All you need is to print the item (i.e. read permissions!).
Exercise 3: Generic Function and Trait Bounds
Implement a generic function that takes some item that a user wants to checkout, and a vector of similar items representing the library. It finds the first matching copy of that item in the vector. Removes it from the vector, and checks it out!
Use this function to checkout a book and a magazine from our library!
Hint: consider implementing a non generic version of this function just for books as a starting point!
Hint: how should you pass the item and the vector of items to the function? Do you need to modify either of them?
Hint: what trait bounds should the generic type satisfy? You need to be able to checkout the type, and you also need to check equality to find a matching copy.
Solution for books only: https://play.rust-lang.org/?version=stable&mode=debug&edition=2024&gist=30eb603812ba9e72b3965252adb50385
Generic solution: https://play.rust-lang.org/?version=stable&mode=debug&edition=2024&gist=435c839e1bd09e80ea6ac0e21a08adbc
Module 10: Computer Memory
Lecture 8: Wednesday, June 3, 2026.
The important concepts we will learn in this module:
- Bits and bytes
- Addresses
- Stack vs Heap
- Allocation, deallocation, and scopes
Motivation
Look at the following program. Feel free to run it using the run icon in the top right corner of the snippet.
fn main() { let x1: i32 = 10; let x2: i32 = 20; let y: i32 = x1 + x2; println!("{y}"); }
This program is really simple: it stores two values, 10 and 20, inside to variables named x1 and x2, both of type i32. It then computes the sum of both and stores it in a variable called y, also of type y. Finally, it prints the value of variable y.
Imagine if you were going to perform this computation the old school way, on a pen and paper without a computer. You would do something like:
- Write down 10 and 20 on the piece of paper, perhaps on top of each other (long addition style)
- You would then do some thinking and add the numbers together, perhaps digit by digit writing down each digit.
- Eventually you will end up with the final answer, 30, written out on a piece of paper.
Crucially, this process required you to write down and operate over different numbers. In other words, you used the paper to store the values. If you had many numbers that you had to deal with (e.g., a balance sheet), you might even given each of these number a name (e.g., balance, revenue, etc), and write that name down next to the number (e.g., in a table or schedule).
The computer executes the program above in a surprisingly similar way to the pen and paper approach! Specifically,
- The computer stores 10 and 20 in its memory.
- The computer retrieves 10 and 20, adds them up (using some process that is quite similar to long addition) and writes the output, 30, to its memory.
- The program writer uses names, such as x1 and x2 (or balance and revenue), to refer to these values and operate on them.
In this analogy, the program memory behaves like the pen and paper, and the variable name behaves like the label, name, or title that we give to the numbers on the piece of paper. In many ways, a computer program is nothing more than a sequence of instructions that tell the computer to store data elements, give them names, and operate on them to produce new data elements, etc.
The pen and paper analogy is surprisingly effective: imagine we kept operating on these numbers and creating new ones for a really long time, eventually, we would run out of paper! Similarly, a computer program that runs for a very long and continually produces new data would eventually run out of memory. Thus, it is crucial that the computer and programmer can free up memory that is no longer needed, a kin to how you would use an erased to get rid of some old numbers on the piece of paper to make space to write down new ones.
Bits and bytes
One major difference between the pen and paper analogy and the computer memory is that computers (and their memory) does not write down numbers (or strings) the way we do on a piece of paper. Instead, they store values in binary encoding using bits. A bit is a single digit that can either be 0 or 1. It turns out we can represent any value you could think of using just bits in binary encoding. Here’s some examples:
the number 0 ====> 0 in binary
the number 1 ====> 1 in binary
the number 2 ====> 10 in binary
the number 3 ====> 11 in binary
the number 4 ====> 100 in binary
the character 'A' ==> 1000001 in binary (using ASCII encoding)
The exact details of how values are encoded in binary using bits is not important for us. What is important is that this encoding exists and is used by the computer. If you are curious, feel free to read more about binary numbers and ASCII encoding for strings.
The most basic unit of memory on a computer is a byte, which is made out of 8 bits. For example, these values are all 1 byte long:
00000000 ===> value 0
00000001 ===> value 1
00000101 ===> value 5
11111111 ===> value 255
In Rust, both i8 and u8 are numeric types that are one byte long. E.g., they represent numeric values that fit in 8 bits.
u8 is for 8-bit long non negative numbers, which range from 0 to 255 inclusive. Values bigger than 255 need more than 8 bits
and thus would not fit inside a variable of type u8. Similarly, i8 represents signed 8-bit long numbers between -128 and 127. Values
outside that range similarly would not fit in 8 bits and thus won’t fit inside an i8.
fn main() { println!("u8 values are between {} and {} inclusive", u8::MIN, u8::MAX); println!("i8 values are between {} and {} inclusive", i8::MIN, i8::MAX); }
Rust similarly has types i16 and u16 (16 bits or 2 bytes long), i32 and u32 (32 bits or 4 bytes long), and i64 and u64 (64 bits or 8 bytes long). Each of these can fit larger and larger values but require more and more space to store.
The smallest unit of space on modern computers is one bytes. This means that values of a type that is logically smaller than a byte, still take up a whole byte of storage. For example, bool can only store true or false (i.e. 1 or 0), and thus could have been as small as a single bit, but it still takes a whole byte (8 bits) on the computer.
fn main() { println!("size of i8 is {} bytes", size_of::<i8>()); println!("size of u8 is {} bytes", size_of::<u8>()); println!("size of i32 is {} bytes", size_of::<i32>()); println!("size of u32 is {} bytes", size_of::<u32>()); println!("size of bool is {} bytes", size_of::<bool>()); }
Computer Memory
So, where does the computer store all these bits and bytes? It turns out, the computer has a hierarchy of storage:
- Hard Disk Drive (HDD) or Solid State Drive (SSD): this is where your computer store your files, such as games or word documents. On modern computers, this is often in the 100s of Gigabytes or even Terabytes. A gigabyte is roughly 1 billion bytes (1 with 9 zeros next to it).
- Random access memory (RAM), sometimes called main memory or just memory: this is where the computer stores all your program variables (numbers, vectors, etc). RAM is often a few Gigabytes (e.g. 8 or 16).
- CPU caches and registers: these are a lot smaller and is where the computer stores values as it operates on them directly (e.g. right when it has to add two numbers). These are not important for this course.
Reading data from a hard drive or SSD is several orders of magnitude slower than reading it from RAM. However, hard drive and SSDs are a lot cheaper (per gigabyte) than RAM. They are also persistent: if you shutdown your computer then turn it on again, you retain all of your files on the hard drive, but lost everything on your RAM!
When we talk about memory in this course, we mean RAM.
So, what does the RAM look like? You can think of RAM is a long strip made out of cells that are each one byte long. In other words, a cell in the RAM would perfectly fit an i8 or u8. On the other hand, an i32 or a u32 would need 4 cells in RAM.
Source: https://www.learncomputerscienceonline.com/what-is-computer-memory/
Because RAM is usually several gigabytes in size, it means that it contains a ridiculously large number of cells, upwards of several billions. Thus,
the computer needs a way to refer to different cells. These are called addresses and in many ways, they work like human addresses.
Imagine the BU campus had a really long road, let’s call it RAM Rd, that has billions of house. The first house would have address 1 RAM Rd, Boston, MA. 02215. The second house would be 2 RAM Rd, Boston, MA. 02215, and so on.
Memory addresses follow the same concept (except, we would not need a road name, city/state, or a zip code). The first cell would have address 0, the second cell would have address 1, the third cell would have address 2, and so on. Because RAM is so big, these address can get quite big. Thus, address on modern computer can be up to 8 bytes (64 bits) in size. In rust, they are often represented using type usize.
fn main() { println!("Addresses are {} bytes in size", size_of::<usize>()); println!("They can range between {} and {} inclusive", usize::MIN, usize::MAX); }
We can confirm this by asking Rust and the computer to show us the address of a variable. Note that because addresses can get really big, Rust prints them in hexadecimal form.
fn main() { let x: u8 = 10; // {:p} instructs Rust to print in address form. // the p stands for pointer, which we will learn about later. // &x asks Rust to give us a pointer/reference/address for x. // we will learn more about pointers and references later. println!("x has address {:p}", &x); }
The Stack
Run the following program and look at the output addresses.
fn main() { let x1: u8 = 10; let x2: u8 = 20; let x3: u32 = 30; let x4: String = String::from("welcome all to DS 210!"); println!("Address of x1 {:p}", &x1); println!("Address of x2 {:p}", &x2); println!("Address of x3 {:p}", &x3); println!("Address of x4 {:p}", &x4); }
We can see the following observations:
- The addresses are ordered: x1 has an earlier (smaller) address, then x2, then x3, then x4.
- x2’s address is one away from x1. Remember that the smallest unit of memory (a cell) is one byte in size.
This means that x1 takes up one byte, followed immediately by x2. This is expected because, x1 has type
u8. - x3’s address is similarly one byte away from x2, as x2 is also a
u8. - x4’s address is 4 bytes away from x3! This is because x3 is a
u32, which requires 4 bytes (thus 4 cells) in memory.
By default, variables in Rust are stored on the stack. The stack is quite nice to use for us programmers:
- It has fast allocation and de-allocation
- It is completely automatic: Rust and the computer automatically figure out where to store new variables and when to free them or get rid of them to save space.
- It is simple to understand because it follows the LIFO principle: Last in First out.
Crucially, each variable or piece of data that Rust stores on the stack needs to have a fixed and known size. So that Rust knows how far away the next variable or value should be from it. This means that data with an unknown size or a size that can change dynamically, cannot be stored on the stack!
The heap
Let’s look at the following code:
fn main() { let x1: i8 = 10; let mut s1: String = String::from("hello"); let x2: i8 = 20; println!("address of x1 {:p}", &x1); println!("address of s1 {:p} and size of s1 {}", &s1, size_of::<String>()); println!("address of x2 {:p}", &x2); }
You can see that s1 appears to be stored in the stack, between x1 and x2. You can also see that s1 is 24 bytes in size.
However, the contents of a string is dynamically adjustable, e.g., we can add more characters to it. If the strings contents were stored on the stack, this could create a problem: new variables (such as x2) may be stored immediately following s1 on the stack, meaning that we
would not have any free space or room to add more elements to the string. Alternatively, if we try to reposition s1 to the end of the stack, e.g., until after x2, we would create a gap of empty but unusable space where s1 used to be and violate LIFO.
As a result, we need a different approach for such dynamically resizable data! Look at the output of this code:
fn main() { let x1: i8 = 10; let mut s1: String = String::from("hello"); let x2: i8 = 20; println!("address of x1 {:p}", &x1); println!("address of s1 {:p} and size of s1 {}", &s1, size_of::<String>()); println!("address of x2 {:p}", &x2); s1.push_str(" everyone!"); println!("address of s1 {:p} and size of s1 {}", &s1, size_of::<String>()); println!("{s1}"); }
Notice the following:
- When we print s1, we see the modified string “hello everyone!”.
- At the same time, the address of
s1remains unchanged. - Furthermore, the size of
s1remains unchanged (24 bytes)!!!!!
This seems wrong! How could the size of the string remain the same even though we just made it a lot longer than it was before?
Well, this is because a string in Rust actually consists of 3 components: the length of the string (the number of characters in it), the
capacity of the string (how much empty space is currently available for the string to grow into), and the address (or pointer, ptr for short) of where the characters of the strings are actually stored! It does not contain the characters of the string
The characters are actually stored in a different part of memory, called the heap:
- Allocation and deallocation to the heap is slower than the stack.
- Heap allocations does need to have a fixed size.
- Heap memory can be allocated and deallocated in any order and not only LIFO.
This allows String to have the best of both words: it has a known and fixed size on the stack, allowing Rust to deal with variables of type string
easily, including automatically adding or removing them from the stack using LIFO. At the same time, it means that the characters of the
string can be dynamically modified and resized, as they are stored on the heap. However, this means that the code of String would need to
manually manage the heap memory, including when to allocate it, when to free it, when to resize it to a new size and move over characters to it,
etc.
Strings are not the only type that behaves this way: any type that deals with dynamic, resizable data must also allocate, manage, and free its own heap memory. This include Vec, HashMap, HashSet and many many other types. You will have hands-on experience with what this entails when you implement FastVec in project 1!
fn main() { let mut v1: Vec<i8> = vec![5, 4]; println!("address of v1 on the stack {:p}", &v1); println!("address of first element of v1 (on the heap) {:p}", &v1[0]); println!("address of second element of v1 (on the heap) {:p}", &v1[1]); }
Scopes
It turns out that every variable in Rust has a scope: this represents a portion of the code where the variable is active and can be used (called in scope). Outside of this portion, a variable is inactive and cannot be used (out of scope).
Rust variables take on the scope of the blocks of code they are defined in. For example, run the code below, then edit it to see what happens if you use variables when they go out of scope!
fn main() { // x1 is in scope until the end of the main function. let x1: i8 = 10; if x1 > 5 { // x2 is in scope inside this if branch, // it cannot be accessed outside of it. let x2: i8 = 20; println!("{x2}"); } println!("{x1}"); // try to print x2 here, what do you see? // println!("{x2}"); for i in 0..3 { // x3 is in scope inside the for loop body, // it cannot be accessed outside of it. let x3: i8 = 30; println!("{x3}"); } // try to print x3 here, what do you see? // println!("{x3}"); { // you can use curley braces to define your nested scope! // x4 is in scope within these curley braces! let x4: i8 = 50; println!("{x4}"); } // end of scope for x4 // try to print x4 here, what do you see? // println!("{x4}"); }
Because a variable cannot be used after it goes out of scope, that means that Rust can erase that variable from memory (and specifically, the stack) to save space! Furthermore, it may chose to reuse that space for a different new variable later.
This gives us the LIFO behavior of the stack: a variable defined later in a program cannot have a bigger scope than an active in-scope variable defined before it. Thus, the later variable will be erased or freed first! To convince yourself of this fact look at the above program. Say we are inside the for loop: there are two active variables, x1 and x3. Notice how x3, which was defined later, goes out of scope earlier than x1.
Furthermore, if a type manages some heap memory, such as Vec or String, it can provide code to free up or deallocate that memory that Rust can automatically invoke when the variable goes out of scope. This is why in Rust, we view variables or values as owning their heap memory and resources.
struct SimpleExample { // imagine we have some resources on the heap // ptr_to_heap: *mut i32, } // We can define our own destructor that tells Rust // how to free/deallocate the heap resources impl Drop for SimpleExample { fn drop(&mut self) { // free(self.ptr_to_heap); println!("destructor called!"); } } fn main() { let x1: SimpleExample = SimpleExample {}; { let x2: SimpleExample = SimpleExample {}; println!("address of x2 {:p}", &x2); } println!("After curley braces"); println!("address of x1 {:p}", &x1); println!("Right before main is over"); }
Module 11: (Unsafe) Pointers
Lecture 8: Wednesday, June 3, 2026, and
Lecture 9: Thursday, June 4, 2026.
This module looks at the following concepts:
- What are pointers and what they useful for?
- Why are pointers dangerous?
Pointers
In the previous module, we learned about the structure of the computer memory, specifically:
- It is made out of 1 byte sized cells, each labeled by unique address.
- It consists of a stack (fixed sized automatic allocation) and a heap (dynamic allocation with manual memory management).
So far, we looked at many programs that store and manipulate data, and while we know now that this data is stored in memory in some cells with an address, we have only referred to them using variable names. For example:
fn main() { let x1: i32 = 10; let x2: i32 = 20; let y: i32 = x1 + x2; println!("{y}"); // This program stores 3 pieces of data, 10, 20, and 30 // in different locations in memory. // We did not need to know where these locations are or what their // addresses are. Instead, we could refer to the values using // their variable names, e.g., x1 and x2. println!("address of x1 {:p}", &x1); println!("address of x2 {:p}", &x2); println!("address of x3 {:p}", &y); }
This was true because we either used fixed size data that is stored on the stack (e.g., x1, x2, and y in the example above are all i32s stored on the stack) or dynamic sized data using Rust provided dynamic types, such as Vec and String. While Vec and String perform a variety of dynamic heap allocations and memory manipulation, they do it behind the scenes so that programmers like us do not have to worry about then.
However, to get better at programming, we have to look at how these manipulation work behind the scenes.
Pointers and Addresses
Look at the below code.
fn main() { let x1: i32 = 10; let ptr_x1: *const i32 = &x1 as *const i32; println!("address of x1 {:p}", &x1); println!("size of x1 {}", size_of::<i32>()); println!("pointer ptr_x1 points to address {:p}", ptr_x1); println!("size of ptr_x1 {}", size_of::<*const i32>()); println!("address of ptr_x1 {:p}", &ptr_x1); }
We have two variables here. The first is x1, which is located at some address.
The second, ptr_x1 has a strange type we have not seen before *const i32.
This type is read as a constant pointer to an i32. ptr_x1 does not actually
contain an i32 inside of it. Instead, it contains a memory address, and if we follow
that memory address, we would find an i32 there.
We can confirm this by looking at the output of the above code:
- The address inside
ptr_x1matches the address ofx1. - The size of
ptr_x1is 8 bytes, which is the size required to store addresses, while an i32 is 4 bytes.
Notice that both x1 and ptr_x1 are variables of a fixed size. They are both stored on the stack.
x1 is stored as 4 bytes that contain the value 10, and ptr_x1 is stored as 8 bytes that contain
the address of x1. We can confirm this by observing that the address of ptr_x1 is 4 bytes after the address of x1.
In other words, the memory layout for this program looks as below.
Dereferencing a Pointer
The most important operation we can do to a pointer is dereference it. This tells the computer to follow the address stored inside the pointer and look at whatever value is stored there.
fn main() { let x1: i32 = 10; let ptr_x1: *const i32 = &x1 as *const i32; unsafe { println!("{}", *ptr_x1); } }
Dereferencing is done using the * operator. So *ptr_x1 tells the computer to dereference ptr_x1, which in this case
leads to x1 and the value 10.
unsafe: Dereferencing a pointer is one of the most dangerous things you can do on a computer: at the time of dereferencing, there is no guarantee
that the address you dereference is a valid address, contains a value of the type you think it does, has its data initialized, or points
to data that has not been modified or used by other parts of the program.
As a result, using it require explicitly using an unsafe block. This tells the compiler to allow us to use unsafe operations that are
potentially dangerous, and that we as programmers will take responsibility for them.
A pointer simply comprises an address of some piece of data. It does not contain any fact or copies of that data. If after creating the pointer, the data the pointers points to changes, dereferencing the pointer would show the new data.
fn main() { let mut x1: i32 = 10; let ptr_x1: *const i32 = &x1 as *const i32; x1 = 30; unsafe { println!("{}", *ptr_x1); } }
We can also use dereferencing to modify the data the pointer points to.
fn main() { let mut x1: i32 = 10; let ptr_x1: *mut i32 = &mut x1 as *mut i32; unsafe { *ptr_x1 = 50; } println!("{x1}"); }
Note that this requires a mutable pointer, instead of a const pointer. Try to change the muts to const in the code above and see what errors the Rust compiler gives you!
Allocating Data on the Heap
As discussed in the previous module, a String or a Vec simply contains a len, capacity, and a pointer to the characters or elements,
which are stored on the heap. This enables dynamically resizing, e.g., by adding many elements to the vector.
fn main() { let mut v: Vec<i32> = vec![10, 20]; v.push(30); println!("{:?}", v); }
After line 2 when the initial vector is created the memory layout looks like this:
Then, after pushing 30 to the vector, the memory layout becomes:
How does this work? Programmers can tell the computer to allocate memory on the heap using a memory allocator (malloc).
fn main() { unsafe { let ptr: *mut i32 = libc::malloc(4) as *mut i32; println!("ptr points to address {:p}", ptr); } }
Allocation, like most pointer operations, is unsafe. When we allocate memory on the heap, we need to tell the computer how many bytes to allocate. In this case, we allocate 4 bytes, which is the size of an i32.
But what values does the allocated memory contain? The answer is –– it depends. Integers are really simple types with a simple memory layouts, allocators often initializes them to 0. However, a more complicated type, such as a string or a vector, may not be initialized properly, because it is more complex, e.g., it contains more pointers inside of it!
Thus, you are not supposed to read data on the heap until you have initialized first, using std::ptr::write(...).
fn main() { unsafe { let my_ptr: *mut String = libc::malloc(size_of::<String>()) as *mut String; println!("my_ptr points to address {:p}", my_ptr); std::ptr::write(my_ptr, String::from("hello!")); println!("{}", *my_ptr); } }
Freeing Data on the Heap
Remember that unlike the stack, the heap is not automatically managed by the computer or Rust.
Thus, if we manually allocate data on the heap, we are responsible for manually freeing it when we are done with it.
fn main() { unsafe { let my_ptr: *mut String = libc::malloc(size_of::<String>()) as *mut String; println!("my_ptr points to address {:p}", my_ptr); std::ptr::write(my_ptr, String::from("hello!")); println!("{}", *my_ptr); libc::free(my_ptr as *mut libc::c_void); } }
However, freeing only frees the memory allocated by malloc. If that memory in of itself contains more pointers to heap allocations, those
will not get freed. For example, the string in the above example does not get properly destructed. To do so, we must remember to
call std::ptr::read(...) before freeing.
fn main() { unsafe { let my_ptr: *mut String = libc::malloc(size_of::<String>()) as *mut String; println!("my_ptr points to address {:p}", my_ptr); std::ptr::write(my_ptr, String::from("hello!")); println!("{}", *my_ptr); std::ptr::read(my_ptr); libc::free(my_ptr as *mut libc::c_void); } }
Pointer Arithmetic
We can also allocate sequence of elements on the heap. For example,
fn main() { unsafe { // Allocate 2 i32s (2 * 4 bytes = 8 bytes). let my_ptr: *mut i32 = libc::malloc(size_of::<i32>() * 2) as *mut i32; println!("address of my_ptr is {:p}", my_ptr); } }
In this case, the returned pointer points to the first one of the two i32s. We can get a pointer to the second one using add(...).
fn main() { unsafe { let ptr0: *mut i32 = libc::malloc(size_of::<i32>() * 2) as *mut i32; let ptr1: *mut i32 = ptr0.add(1); println!("address of ptr0 is {:p}", ptr0); println!("address of ptr1 is {:p}", ptr1); } }
Notice how ptr1 is 4 bytes (i.e., one i32 value) away from ptr0.
Remember that this kind of pointer manipulations can be very dangerous. What if we moved the pointer forward too much and got outside the allocated region? It is your job as a programmer to ensure this does not happen!
You will have a chance to practice dealing with pointers extensively when implementing the FastVec project.
Why are Pointers Dangerous?
The reason pointers are really dangerous is that the Rust compiler cannot guarantee whether they point to valid data or not.
For example, the pointer may point to data that was freed, ran out of scope and was destroyed, or be the result of some operation that take it out of range.
For example, one of the most common mistakes programmers in pointer-based languages make is to double-free. If you run the above program, you will see that it unexpectedly crash due to a double freeing error!
fn main() { unsafe { let ptr0: *mut i32 = libc::malloc(size_of::<i32>() * 2) as *mut i32; libc::free(ptr0 as *mut libc::c_void); libc::free(ptr0 as *mut libc::c_void); } }
More serious errors are also possible (and sometimes easy to make). Consider the below program.
fn main() { let mut ptr: *mut Vec<i32> = std::ptr::null_mut(); { let mut v: Vec<i32> = vec![1, 2, 3, 4, 5]; ptr = &mut v as *mut Vec<i32>; // v goes out of scope here and gets destroyed. } println!("ptr is now a dangling ptr"); unsafe { println!("{}", (&*ptr)[0]); } }
To avoid these issues, Rust actively dissuades the use of raw pointers. Instead, Rust encourages us to use its safe references, a pointer like concept that provides many of the advantages of pointers without the risk!
We will see references in more detail in the next module.
Discussion 1: Git Basics
Discussion 1: Tuesday, May 26, 2026.
This exercise is designed to help you get familiar with using git and GitHub.
To complete this exercise, you need to install git on your computer, if you haven’t already. Follow this link to install git.
Submit your work on Gradescope.
Part 1: Git-It Challenge
For this part of the assignment, you will learn and practice git commands using the Git-It tutorial. We forked and made some minor changes to the program.
Download the zip file from the Assets section of our Releases page. Follow the installation instructions for your machine.
MacOS Installation
- Download
git-it-darwin-arm64.zipto your Downloads folder. - Follow this video on how to unzip and start the app.
Windows Installation
- Download
git-it-win32-ia32.zip. - Follow this video on how to unzip and start the app.
- The command used in the video is
xattr -cr Git-it-darwin-arm64/Git-it.appfrom the Downloads folder.
- The command used in the video is
Your submissions
- Take a screenshot of the Git-It app showing your completion status and upload it to Gradescope.
- Paste the output of
git logfrom your localhello-worldproject into Gradescope. - Paste the output of
git logfrom your localpatchworkfolder into Gradescope.
Part 2: Fork and Edit Our GitHub Repository
Follow these steps:
- Use GitHub to fork our course’s code repository: https://github.com/rust4ds/ds210-sum26-code
- Clone the fork you created to your computer using
git clone. - Navigate to the directory of the repo on your computer and create a file called
hello.mdwith this content:
# hello!
This is my first git file
-
Add, commit, and push the file:
git add hello.md git commit -m "your commit message" git pushUse a meaningful commit message.
-
Confirm that
hello.mdhas been pushed to your fork on GitHub.
When you are done, submit the URL to your fork on GitHub to Gradescope.
Discussion 2: Leetcode!
Discussion 2: Thursday, May 28, 2026.
This discussion section works through Leetcode-style programming exercises in Rust.
Submit your work on Gradescope.
Part 1: Missing Number
Solve the Missing Number problem on Leetcode.
Hint: consider using a
HashMapor aHashSet!
Upload a screenshot of your submission getting accepted on Leetcode to Gradescope.
Part 2: Kth Largest Number
Solve the Kth Largest Element in an Array problem on Leetcode.
Consider using a BinaryHeap — a data structure that allows you to insert and remove elements by their relative order.
Here is an example of how to use it.
Upload a screenshot of your submission getting accepted on Leetcode to Gradescope.
Discussion 3: LinkedList
Discussion 3: Thursday, June 4, 2026.
In this discussion you will implement a singly linked list in Rust using raw pointers and manual memory management. This exercise is great preparation for the upcoming Vec project, where you will manage heap memory directly in a similar way.
Clone the course code repository and navigate to the linked_list directory to get started:
git clone https://github.com/rust4ds/ds210-sum26-code.git
cd discussion_3_linked_list
When you are done, zip the src directory and submit it to Gradescope.
Part 1: Simple Linked List
Implement get and push_back in src/simple_linked_list.rs.
The struct definitions and push_front are already provided. Nodes are heap-allocated using MALLOC.malloc, the same custom allocator you will use in the Vec project. Take a look at push_front to understand the pattern before writing your own code.
get(i) — return a raw pointer to the node at index i. Traverse the list one step at a time. If i is out of bounds, panic.
push_back(value) — allocate a new node and append it to the end of the list. Think about the empty list as a special case.
To test and run:
cargo test --test simple
cargo run --bin simple_main --release
The simple_main binary compares the performance of your linked list against a Vec for len, get, push_back, and push_front. Look at the timing results and think about why each operation takes as long as it does for each data structure. Do the results match your expectations? Take a screenshot of the output and upload it to Gradescope.
Part 2: O(1) len and push_back
Look at the timing results from Part 1 and analyze the runtime of each operation on your linked list. Which ones could be made faster? How would you do it?
For this part, make len() and push_back() run in O(1) time. Hint: consider storing additional metadata in the LinkedList struct.
Run simple_main again after your changes and compare the timings to Part 1. Take a screenshot of the new output and upload it to Gradescope.
Part 3: Remove
Implement remove in src/remove_linked_list.rs. The remove_head function is already provided — read it carefully.
remove(i) — remove the node at index i. Think carefully about all the cases your implementation needs to handle.
Start by running the tests to make sure your implementation is correct:
cargo test --test remove
Then run the binary and look at the output carefully:
cargo run --bin remove_main
Is there a memory leak? If so, think about what is causing it and how to fix it. The fix applies to both remove and remove_head. Apply it, then run the tests and the binary again to confirm everything is correct.
Part 4: Drop
Run the drop_main binary:
cargo run --bin drop_main
Look at the output — is there a memory leak? Why is it happening?
Rust allows you to run custom cleanup code when a value goes out of scope by implementing the
Drop trait. Implement Drop for LinkedList in src/drop_linked_list.rs, then run drop_main again to confirm there is no longer a leak.
Project 1: Guessing Game
In this assignment, you will:
- Implement different strategies for solving “the guessing game”.
- Write tests to ensure your strategies are correct.
- Evaluate which strategy performs better in the worst case.
The Guessing Game
The game is pretty simple. The user (you!) is the challenger player: they select a random number and write it down. The computer then tries to guess the number by asking the user a series of questions. The goal of this game is to:
- Write a computer strategy that guesses the number correctly.
- Have the strategy reach this guess while only asking a small number of questions.
Here are the important concepts in this game:
The number: the target number the computer must correctly guess.The player: the entity that chooses the target number and answers questions about it. This is usually the user (you!).The strategy: the program the computer follows to guess the number. The strategy can chose to try different options and ask the player questions about them.The guess: the final answer the strategy returns, which should be equal tothe number.# of steps: how many questions the strategy needed to ask the player before returningthe guess.
Provided Code
We provide you with a lot of scaffolding code (this is often called a stencil) for the game as well as some examples. The provided code is under project_1_guessing_game in our course’s GitHub repo https://github.com/rust4ds/ds210-sum26-code
The code has the following structure:
src/game.rs: This is the main file for playing the game. It initializes the player and strategies, and prompts the user with instructions. You do not need to read or understand this code to complete the assignment.src/strategies.rs: This file contains two provided strategies. We suggest reading and understanding lines 15-35.BadStrategy: This strategy checks if the number is the smallest number in the range, otherwise, it just assumes it is the maximum. This is a bad and incorrect strategy that cannot guess most numbers!RandomStrategy: The strategy chooses a potential guess at random, asks the user if it is correct, and repeats until it finds the number.
src/player.rs: This defines the interface for what questions a player needs to answer. It also provides the logic underHumanPlayerfor how to print out questions to the user and how to retrieve their answers. You do not need to understand this file deeply, but feel free to skim it.src/experiment.rs: This files contains the code to evaluate which strategy is best, which you will need to run and use for part4.src/part<i>.rs: This is where you need to add your code for parts 1 through 4.
Do not modify any files other than src/part<i>.rs. Our autograder will completely disregard any modifications to the other files you make.
After you are done, you need to submit each src/part<i>.rs file via Gradescope.
Instructions
Part 0: Getting Started
Downloading the Stencil
Step 1
Our course’s GitHub repository has all the project stencils as well as code from class and from discussions. The repository is available at https://github.com/rust4ds/ds210-sum26-code.
You can download the code from the repository as a zip file following the steps shown in the screenshot below.
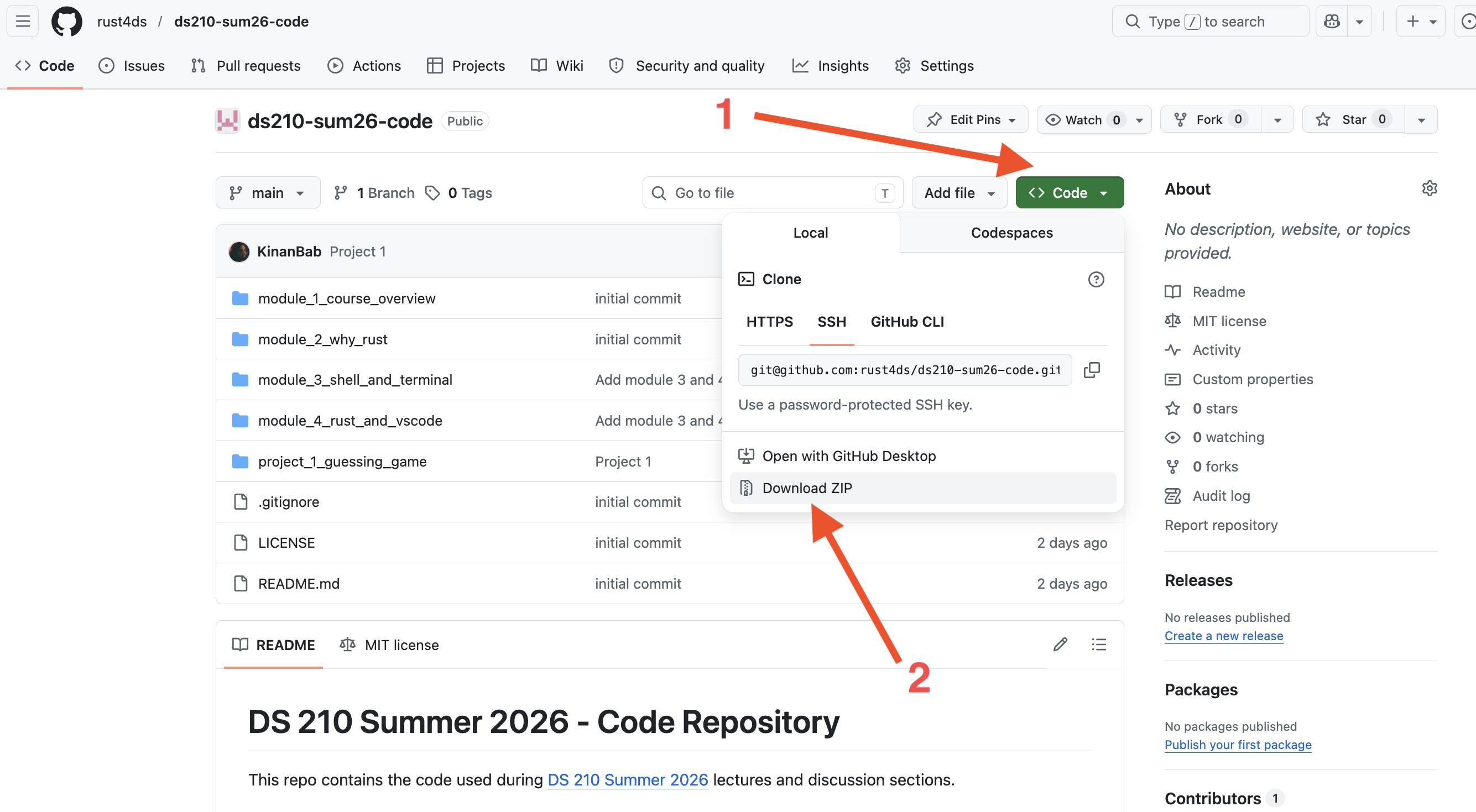
Extract the contents of the zip file and put them in a directory of your choosing on your computer. I chose to put the code in my Desktop.
Opening the code with VSCode
Open the project 3 folder using VSCode. Make sure you open the project folder and not a file inside it.
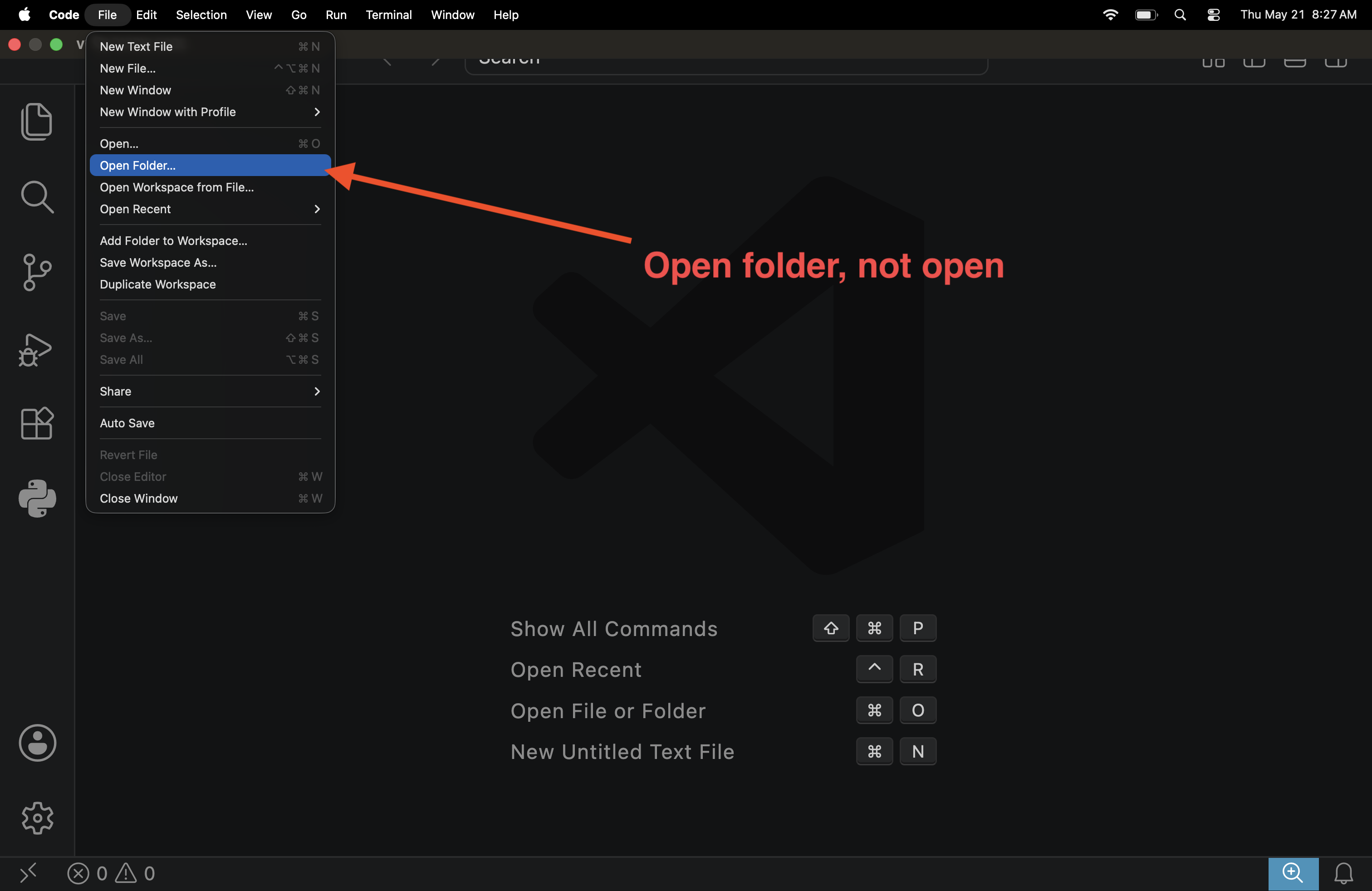
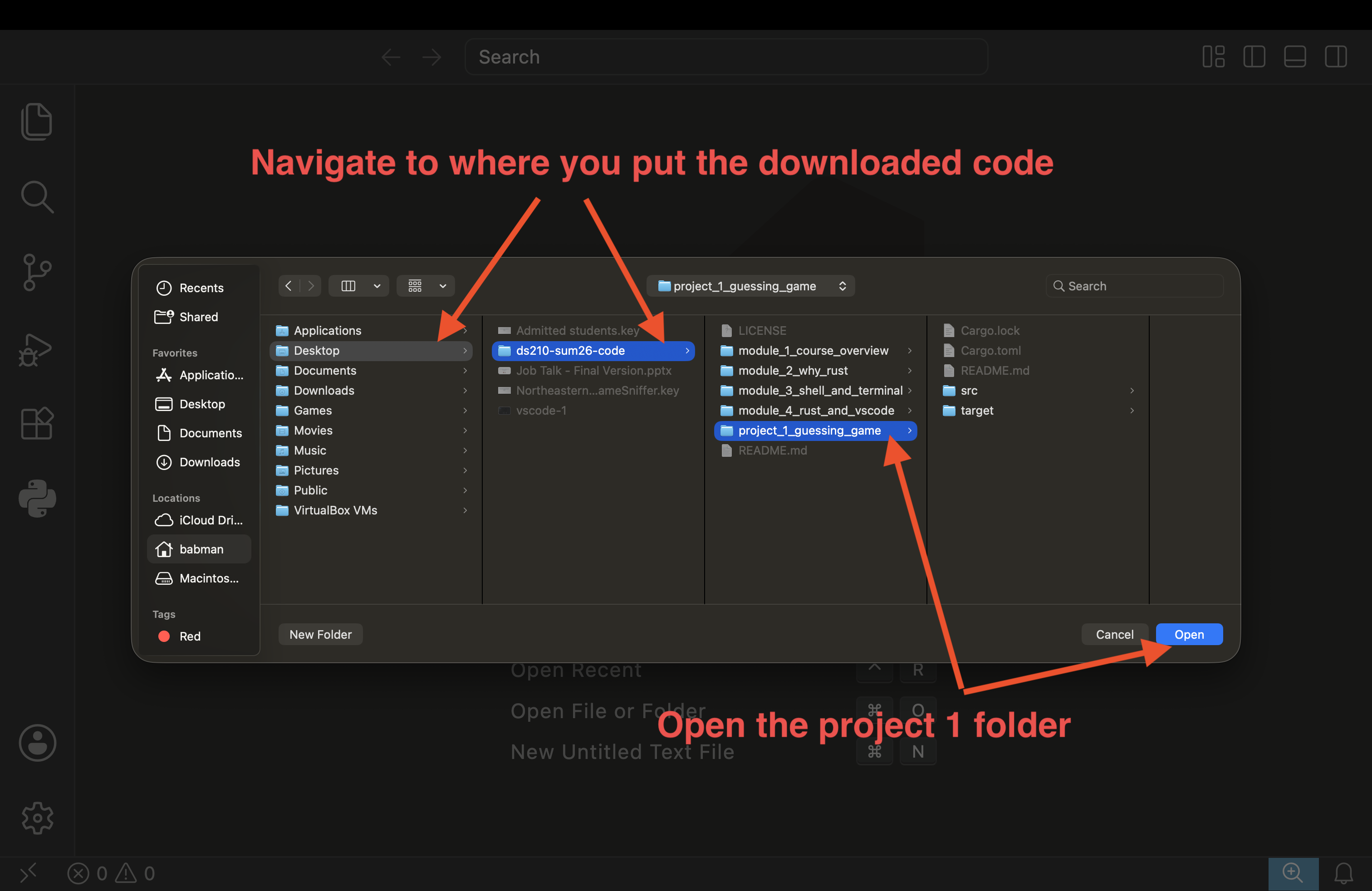
Then, select src/part1.rs from the VSCode navigation panel (on the left of the screen), you should be able to see the content of the file.
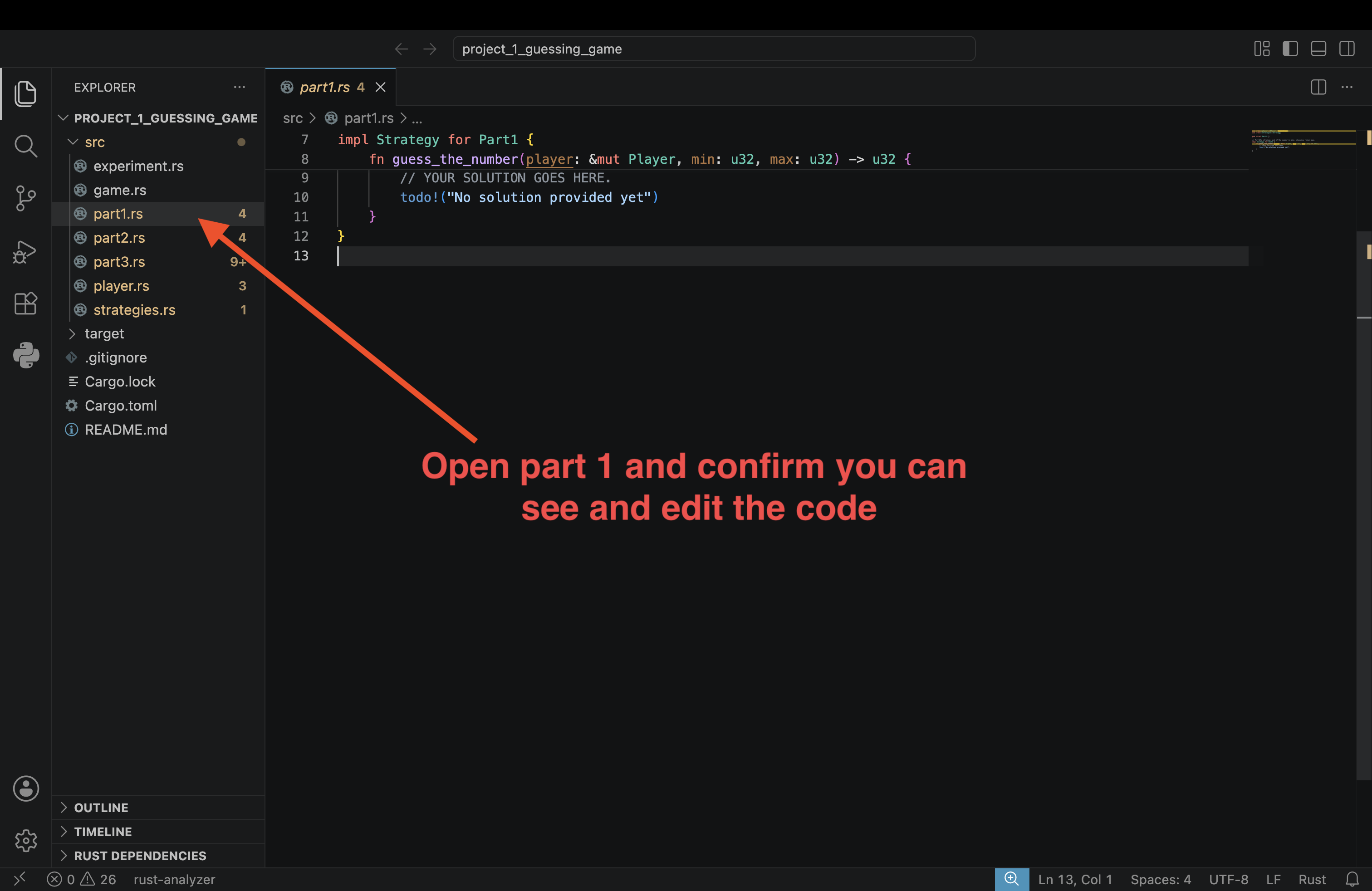
Playing the Game for The First Time
After you successfully opened the stencil with VSCode, you can start playing the game.
First, use the following command to run the game the first time. You can use the terminal built into VSCode to execute it:
cargo run --bin game -- --strategy random
After you run the command, Rust may need a few minutes to compile the program, then the game will start, follow the prompts
to play the game, as shown in the screenshot below. Make sure you navigate to the project folder.
Use pwd to confirm your current location, and cd <PATH OF YOUR CHOICE> to change folder/directory.
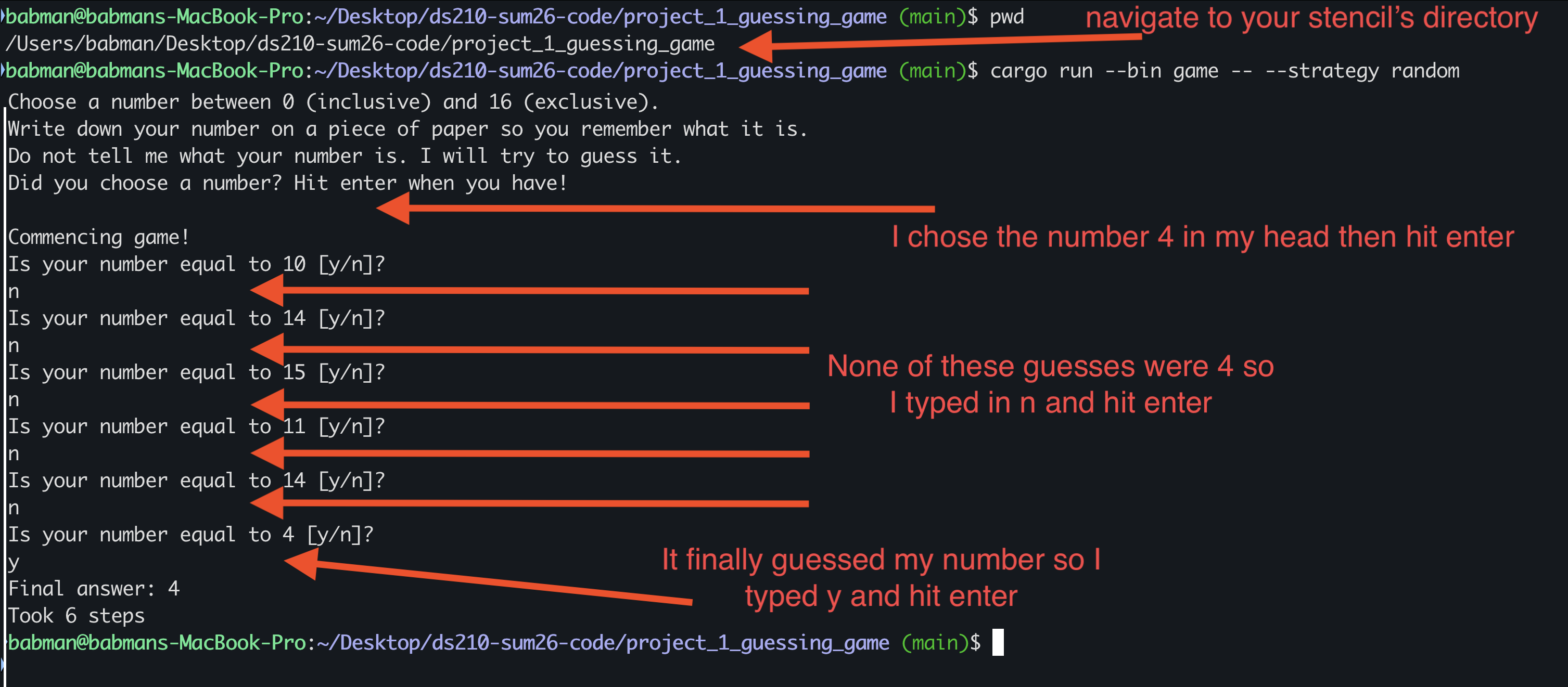
It turns out, the game supports other strategies and other configurations, use this command to list them:
cargo run --bin game -- --help
Try out a couple of different configurations to get a sense of what the game is like, for example:
cargo run --bin game -- --strategy random --min 5 --max 10
cargo run --bin game -- --strategy bad --min 2 --max 6
Finally, after you are done playing the game, try these two commands:
cargo run --bin game -- --strategy part1
cargo run --bin game -- --strategy part2
Both commands will produce an not yet implemented error! This is because it is your job in this assignment to implement these two strategies, as described below!
Part 1: The “Gotta Try Them All” Strategy
If you played the game a few times as described above, it will become clear to you that:
- The
randomstrategy often takes a long time before finding the answer, often repeating bad guesses! - The
badstrategy is actually bad, and will incorrectly return answers that are wrong.
We can do better! We will think of a better strategy and implement it in src/part1.rs.
Add your solution inside the guess_the_number function (line 8).
You should remove the todo! (line 10) and replace it with your solution.
For part 1, you are tasked to implement the following strategy:
- Iterate/loop over numbers between min (inclusive) and max (exclusive).
- For each of these possibilities, ask the player if the possibility is equal to their number.
- If it is, congratulations, you found the answer! return it.
- If it is not, continue iterating to the next guess.
Hint: Look at the random strategy in src/strategies.rs (e.g. line 30) to find how you can ask the player
if the possibility equals their number.
Hint: Feel free to return some number of your choosing at the end of the function after your loop to make sure the Rust compiler is happy: your code will try all the possibilities, and one of them will be the answer, so it will never get to that point!
You can test your solution by playing the game and confirming that it always finds the right answer. Do not
forget to experiment with different values for min and max!
cargo run --bin game -- --strategy part1
When you are happy with your solution, do not forget to save it, commit it, and push it to your fork using Git. This way you will never lose it!
git add src/part1.rs
git commit -m "solution for part1"
git push
Part 2: A More Sophisticated Strategy
Part1’s strategy always produces the correct result, and is a significant improvement over random. However, if your number is big, it will take many questions before it gets to your number.
Imagine you were running with min 0 and max 64, and your number was 60. You will have to answer many questions
before the strategy finds the answer.
It turns out we can do way better, if we can ask more expressive questions.
Indeed, we provide you with player.ask_to_compare(...) function that does exactly that.
This function returns 0 if the guess equals the number, -1 if the number is smaller than the guess, and
1 if the number is greater than the guess.
// Assume the number is 4
let x1 = player.ask_to_compare(5);
let x2 = player.ask_to_compare(4);
let x3 = player.ask_to_compare(0);
// x1 is 1, x2 is 0, and x3 is -1How can you use this to your advantage to derive a better strategy? Implement your solution in src/part2.rs.
Hint: Imagine you ask the player to compare their number to the middle of min and max. What does it mean when the comparison
returned -1 vs 0 vs 1?
Hint: Can you repeat the above reasoning again for the next step? What about the step after it?
Hint: This idea is one of the most powerful and common ideas in programming, and has many names, e.g., binary search or
bisection.
Hint: You can code this up in many ways, but it might be simplest to code using recursion.
You can test your solution by playing the game and confirming that it always finds the right answer. Do not
forget to experiment with different values for min and max! Notice any difference with part1?
cargo run --bin game -- --strategy part2
Part 3: Testing strategies and why tests are important
Simulating a player
Let’s assume we want to test or experiment with our strategies at scale. E.g., with max = 1000.
Currently, the bottleneck is that whenever we run the game, a human user (you) has to type in y and n or other answers
to questions manually.
We can improve this by implementing a simulated player that returns the answer to different questions programmatically, without
involving the user.
Open src/part3.rs using VSCode, and complete SimulatedPlayer implementation of ask_if_equal(...) and ask_to_compare(...).
These are different than the functions we have seen in class. They are member functions that are part of SimulatedPlayer. We will cover these in more depth in class later.
For the purposes of this assignment, you can think of them as regular functions that take a special self parameter. Think of this
self parameter as “simulating” the state of mind of the user player. Specifically, this self parameter is where we
will keep our simulated number!
You can access this simulated number using self.the_number. For example, you can print that number or compare it against a guess
using the following code:
println!("{}", self.the_number);
let is_equal = self.the_number == guess;Hint: Mimic is_equal above to implement ask_if_equal(...).
Hint: There are three different cases in ask_to_compare(...). What are they?
Testing part1 using the simulated player
After you implement your simulated player, you should be able to run our provided tests for part 1.
cargo test --bin game part1 -- --test-threads=1
If your implementation of part1 and your implementation of the SimulatedPlayer, you should see the three tests passing.
If they do not pass, you have a bug! Go back to your code and see if you can spot it and fix it. Consider testing part1
manually by playing the game a few times.

You can look at the content of these tests in src/part3.rs inside the block of code that says mod part1_tests. Read the code
slowly and try to take it in:
- There are three functions:
the_min,the_max, anda_different_number. Each correspond to one test case. - Their logic is similar, they set the parameters of the game:
min,max, and the simulatednumber. Then, they create aSimulatedPlayerwith that number. Finally, they call your part1 strategy and give it the simulated player!
Testing the bad strategy
We also provide tests for the bad strategy and for part2! However, those are incomplete and you have to add some
of their missing logic.
First, run the bad strategy tests.
cargo test --bin game bad -- --test-threads=1
You will notice that two tests the_min and the_max pass. This is not good! Had these been the only tests that we have,
we would not be able to detect that the bad strategy is bad!
Your task is to implement the missing logic (i.e., replace the todo!) in the remaining test bad_strategy_tests::a_different_number.
Your new logic should detect that bad_strategy does not work!
Run the tests again after you update the logic. Confirm that bad_strategy_tests::a_different_number fails! When you are happy with the test,
add #[should_panic] on top of the test’s function, to indicate to Rust that this test should fail. After you do that, the tests
should now pass.
#[test]
#[should_panic]
fn a_different_number() {
// your logic goes here
}
Testing the part2 strategy
Finally, you must complete the last three tests at the end of src/part3.rs. These must test part2.
Feel free to mimic the tests we provide for part1, but make sure that
- You call the
part2strategy, and notpart1. - You test that the number of steps the strategy take is small! Mimic how the tests we provide for part1 check the number of steps, but use an appropriate smaller bound.
You can run your tests using the below command. Make sure they pass!
cargo test --bin game part2 -- --test-threads=1
FYI: We will test your tests against various correct and incorrect implementations of part1 and part2. You will receive full credit if your tests accept all the correct implementations, and fail for all the incorrect implementation. Furthermore, one of the implementations we will provide for part2 will find the correct answer, but it will take many extra steps, and your tests must correctly detect this and fail/error.
Part 4: Evaluating strategies performance
After you complete the SimulatedPlayer implementation in src/part3.rs above, you can run our provided experiment to compare
the part1, part2, and random strategies.
You can run our experiment using this command:
cargo run --bin experiment
The command will create a new file plot.png. On my computer, this was created at this path
/Users/babman/Desktop/DS210/project_1_guessing_game/plot.png. If you placed the stencil in a different directory or path,
the plot will be produced in the corresponding location.
Open the plot and look at it.
The X axis shows the max: our experiment tries all values between 1 and 100. The Y axis shows how many questions each
strategy took before it returned the answer.
Answer the following questions. For each question, write about 2-3 sentences explaining your answer. You will submit these answers via Gradescope.
Question 1: Which strategy is the best?
Question 2: For part1, assume that max = 110, can you use the plot to predict how many questions the strategy will ask? What about max = 120?
Generalizing this to max = n, can you find the number of questions as a function of n?
Question 3: For part2, many values of max end up with the same number of questions. However, the number goes up every now and then. Can you find the
identify the different values of max when an increase occurs?
Hint: counting max = 1, there are 7 such “levels”.
Question 4: Is there a pattern to the levels in part2? Try to guess when the next level will occur. Using this knowledge, if max = n,
can you estimate how many questions the strategy will ask as a function of n?
Hint: it has something to do with the powers of 2. Feel free to look online for help.
Question 5: Is there anything interesting about the random strategy? Is it sometimes better than part1 or part2? Can you describe a small change
to it that you think would improve it?
Hint: play the game with the random strategy again. What is the most annoying thing about it?
Submission
Congratulations! You are done with this assignment.
You can double check your work by running all the tests in one go. Confirm that all of them pass.
cargo test --bin game
Then, submit part1.rs, part2.rs, part3.rs, plot.png, and your answers to the questions in part4 via Gradescope!
Make sure you have not modifies any of the other game files before submitting.
Mini Project 2: Build your own AI Chatbot!
In this homework, you will:
- Build three versions of a basic AI chatbot of increasing complexity.
- Write user conversation history with the chatbot to persistent storage and cache hot conversations.
Pre-requisites
This project will reuse concepts we have seen before: structs, HashMaps, and Option.
In addition, you will encounter Result. You will also encounter async/await. However, you won’t have to use either of these concepts deeply. The instructions will give you some hints as to how to use them, but feel free to skim the above link when needed.
Part 0 - Setup
Forking the repository: If you have not already done so, fork our course repository on GitHub.
Ensure your fork is synchronized with the latest version of the course repository. You must be able to see project_2_chatbot in the GitHub web UI of your fork after doing this.
Installation: Clone your fork to your computer. Navigate to the directory where you cloned the repo and confirm that you can see project_2_chatbot.
Then, using a terminal, execute the following commands:
cd project_2_chatbot
cd basic_chatbot
cargo run --release --features v1
This will:
- Build/compile the stencil code. This may take up to 2-5 minutes on your computer.
- Run v1 of the chatbot for the very first time on your computer.
- Because it is the first run, the stencil code will download a Llama LLM to your computer. This may take 2-10 minutes on your computer, depending on your network connection. You will see a progress bar in your terminal showing you the progress of this download.
All in all, this may take anywhere between a few minutes to a quarter of an hour on your computer. Please do this early to avoid any surprises.
After all the steps are complete, you should see Rocket has launched from http://127.0.0.1:3000 printed in your terminal, as shown in the screenshot below.
Open your favorite web browser (preferably Firefox or Chrome, but certainly not Internet Explorer or Edge, because we are not savages) and navigate to http://127.0.0.1:3000. This will show you our chatbot web interface (shown below!)
Login using any username of your choosing, then send some messages to the chatbot. As you can see in the screenshot above, the chatbot is not currently functional. Your task is to make it a functional AI chatbot!
Committing your work: Commit and push your work frequently throughout this project, for example, after finishing each chatbot version. This will be part of your grade: we expect at least one commit per version (V1 through V5) with a reasonable commit message describing what you implemented.
Part 1 - Basic Chatbot
V1
Create a new branch called basic_chatbot off of main. You will do all your work for Part 1 on this branch.
Open basic_chatbot using open folder in your VSCode, then navigate to src/solution/v1.rs.
You will see our provided stencil for v1, which includes:
- A
ChatbotV1struct: this represents the version 1 of your Chatbot. It stores the Llama LLM model inside of it as a field calledmodel. - A
newfunction that is a member ofChatbotV1: this function is implemented for you and the stencil executes it once when the website is launched for the very first time to construct your chatbot. - A
chat_with_userfunction that is a member ofChatbotV1: you will have to implement this function. - Several
#[allow(dead_code)]: this tells the Rust compiler not to show you irrelevant warnings if you choose to use a different version of the chatbot later on. You can ignore this.
The provided stencil code uses an external library called kalosm (see line 1). This is a library for managing
and using LLMs from Rust. The Rust compiler already installed this library for you automatically during Part 0.
Let’s look a little more carefully at chat_with_user:
async: this function signature (line 15) uses pub async fn instead of pub fn which we are familiar with. This means that this function is an asynchronous function. Essentially, this tells Rust that this function may take a long time, and so while it executes, Rust can run other functions alongside it.
We have to use async because kalosm is an asynchronous library. The developers of kalosm decided this because invoking an LLM takes a lot of work and time, especially on regular computers and using CPUs.
Thus, the kalosm developers wanted to allow applications to perform other tasks in the meantime, in order to save some time.
message: String: the chat_with_user function receives two arguments. The first is self, representing the instance of ChatbotV1 this function is called over (we have seen this before with project 1 and structs). The second is message, which contains the message the user wants to send to the chatbot and LLM.
You can confirm this by adding println!("{message}");, re-running the chatbot using cargo run --release --features v1, and then sending some messages and looking at the printed output in the terminal.
chat_session: This variable contains a Chat object. This is the interface/type that the kalosm library provides to manage and use chat sessions with the LLM. The exact type of this variable is kalosm::language::Chat<Llama>, which indicates that it is a chat session with a Llama LLM, but you can skip the kalosm::language:: part and write Chat<Llama> instead, because of the use statement on line 1.
with_system_prompt: lines 16-18 show you how the chat_session variable is initialized. We create a new chat model from the llama model we had previously stored inside self (when the Chatbot was first created using new). We then configure it to use the system prompt The assistant will act like a pirate (because I like pirates).
Your task is to complete the implementation of chat_with_user by passing the user-provided message to the chat session, and then retrieving and returning the LLM response.
We suggest you look at the add_message function provided by the kalosm library. Look at the given example for how it can be used.
The add_message function returns the response asynchronously. You can instruct Rust to wait until that entire response is ready by invoking .await on what it returns. For example
let asynchronous_output = chat_session.add_message(...);
let output = asynchronous_output.await;
// notice lack of (), await is not a function; it is a special keyword!Look at the type of output. How can you extract the response message string from it? Hint: it is similar to (but not exactly the same as) Option and can be dealt with using the same approaches we have seen before for Option.
Testing your chatbot: use cargo run --release --features v1 to test your chatbot. Send different messages and see if your chatbot behaves normally. Feel free to change the system prompt so the chatbot is something other than a pirate if you would like.
What happens if you ask the chatbot about something you or it had said earlier? Try telling it your name then ask it to repeat it later and see what happens.
V2
Continue working on your basic_chatbot branch.
When testing V1, you would have noticed that the chatbot has no memory! It does not remember anything you said before. There is a good reason for this: whenever you send a new message, the stencil code calls chat_with_user. Each of these calls creates a new chat_session — a blank slate! It then adds the new message to that session but then discards the session as it goes out of scope.
To make sure the chatbot has some memory, you will need to retain the chat session (notably, the message history inside it!) between calls to chat_with_user. You do not want to lose the chat_session from previous calls; instead, you want to reuse it.
Navigate to src/solution/v2.rs in VSCode. You will notice that this stencil is a lot more empty than the previous one: this is by design. It gives you the freedom to implement the chatbot any way you like, and importantly, the freedom to store whatever you want inside the ChatbotV2 struct.
Decide what type to store inside ChatbotV2. Then, find a way to initialize that data correctly inside the new function. Finally, copy in the implementation of chat_with_user from v1, and adapt it to the new struct in v2.
Hint: you need to store the Chat object itself across calls, not just the message history. The Chat object is what the LLM uses to continue a conversation, and without it, each call to chat_with_user starts fresh.
Testing your solution: Use this command to test your solution:
cargo run --release --features v2
You should test to ensure that your chatbot remembers things you had said previously.
Additionally, do the following test. Run the chatbot, open your browser and navigate to the chatbot page, then login using your name and tell the chatbot something about you: your name or favorite color, etc.
Then, in a new tab, navigate to the chatbot page again, and log in using a different username, for example, Sophie. Do not tell the chatbot anything. Instead, just ask it for your name or favorite color. See what happens! Is this behavior good behavior? Can you think of any problems that may arise from it in practice?
V3
As your testing in V2 should have shown: your chatbot now has memory, but it cannot distinguish between the histories of different users! It is all mashed together! In V3, your task is to separate this memory by user.
Navigate your VSCode to src/solution/v3.rs. You will notice that this stencil code is also nearly empty, giving you freedom to store and manage whatever data and state you want within the ChatbotV3 struct. You will also notice that chat_with_user here takes one extra argument: username.
Decide what kind of data you want to store in the struct and implement the struct definition and the new function.
Hint: do you think you can achieve the desired functionality while storing only one chat session? Do you need more sessions? How many do you need? Hint: should there be some linking between the username and the corresponding chat session?
After completing the struct definition and new function, implement both chat_with_user and get_history.
chat_with_user: you need to retrieve the correct chat session. After that, you should add the message to it and retrieve the response similarly to v1 and v2.
Hint: what if this is the very first message a user sends? Hint: what if this is the second (or later) message a user sends?
You can test your code using the same workflow as v2: login as two users from two different tabs and see if the chatbot leaks information about one user to the other. Note: your chatbot should still remember information sent by the same user within the same tab.
get_history: you need to retrieve the chat session as well. Then, rather than adding a message, you need to retrieve and return the history of the user’s conversation so far as a vector of strings Vec<String>.
We suggest you look at the session function from kalosm and its history function. Look at the examples provided by kalosm in the two links above for inspiration. Consider printing the history using println!("{:?}", YOUR HISTORY VARIABLE);.
This function’s purpose is to display the history in the UI after a user logs back in (see property 3 in the description below). Note that it cannot be fully tested until chat_with_user is also complete.
Testing and Submission
When you are happy with your v3 implementation, do some manual testing by running the below command and opening several tabs to chat with the chatbot concurrently:
cargo run --release --features v3
Verify that your v3 solution meets these properties:
- The chatbot never reveals information given to it by one user to a different user, no matter how persuasive that second user is.
- The chatbot remembers earlier information given to it by the same user. If it does not,
chat_with_userhas some bug that needs fixing! - After you chat with the chatbot as some specific user, say
Sophie, you can refresh the page (or open a new tab) and log in as that same user again, and you will see all of your previous messaging history in the page. If this does not work, thenget_historyhas some bug that needs fixing!
Feel free to apply fixes and push them to your basic_chatbot branch.
It is also a good idea to run v1 and v2 one or two times again after you are done with all changes, just in case.
When you are done with Part 1, open a pull request from basic_chatbot to main. Your instructor will review it after you are done. Then, create a new branch complete_chatbot off of basic_chatbot, which you will use for Part 2.
Part 2 - Storing and Caching History
In the previous part, you implemented a chatbot that keeps track of conversation history for each user independently.
However, one down side of the v3 implementation is that if the Rust application is terminated, i.e. by closing the terminal you ran it from, and then restarted again (by calling cargo run ...), the entire history is lost.
The reason this happens is that the history is saved inside your chatbot struct (and more specifically, inside a variable in the stencil code that contains an instance of your struct). Like all variables in any program, this data is lost when the program is closed or terminated.
To fix this, we will need to save the data to a file, so that it survives the program even if the program is terminated, and then read the data from that file in future executions of the program.
Work on your complete_chatbot branch (branched off basic_chatbot at the end of Part 1).
V4 - File Chatbot
Start by implementing the missing code in file_library.rs and v4.rs, both located under file_chatbot/src/solution/. The comments in the code point you towards helpful functions provided by the Kalosm library for writing and loading a LlamaChatSession to and from bytes, as well as to fs::write and fs::read for writing and reading bytes to and from a file.
Implement all four functions: chat_with_user, save_chat_session_to_file, get_history, and load_chat_session_from_file.
Once you have implemented all four functions, run the provided history test to check for basic correctness:
cd file_chatbot/
cargo test --test history
If the test passes, move on to manual testing:
cargo run --release
# open http://127.0.0.1:3000 in your browser, log in as a user and send a few messages
# kill the server with ctrl+c
cargo run --release
# log back in as the same user — your history should still be there and the chatbot should remember what you told it
# if you log in as a different user, you should not see that history
# repeat this a few more times: send more messages, kill, restart, resume
As you do more rounds of this, you may notice something unexpected happening. You can also run the following test to surface this more clearly:
cargo test --test bug
Read the test output carefully to understand what is going wrong. This is actually a bug in Kalosm’s with_session() function: it does not behave correctly when you try to resume a previous session.
To work around it, we provide a helper function called fixed_load_session in the fix package. You can find it in fix/src/lib.rs. Read it to understand how it works and then use it in your v4.rs implementation in place of with_session().
Confirm the fix works by re-running both tests:
cargo test
V5 - Cache Chatbot
Reading and writing to a file is actually a lot slower than interacting with data stored inside a variable!
If computer memory was unlimited, one could just keep (a copy of) all the conversations in the memory of the program. However, memory is limited, and if there are thousands or millions of users, the conversations would easily fill up the memory.
A common alternative that programmers use is to employ caching: The overall idea is to keep only the needed conversations in the program’s memory (e.g., inside a variable or data-structure of some kind, like a HashMap or a Vector)
One challenge is it is difficult to predict with certainty which conversations are going to be needed in the future, and which ones are not going to be needed. Instead, we have to try to make guesses. Specifically, to guess which conversations should be cached (kept in memory) and which should not be (not kept in memory, and instead have to be read from files).
A popular and easy-to-understand caching strategy is least recently used (LRU). Here, if the limit on cached conversations is reached, the next time we see a new conversation that we need to cache, we would need to (1) make space for it by kicking out a previous conversation (often called evicting) and (2) put the new conversation in its place.
So, which conversation should we kick out? The LRU strategy is to kick out the least recently used conversation. You can see an example of this in action at this link. Feel free to skip over the parts titled Thoughts about Implementation Using Arrays, Hashing and/or Heap, Efficient Solution - Using Doubly Linked List and Hashing, and Time Complexity.
We will implement this strategy inside cache_chatbot. Rather than building an LRU cache from scratch, we use the
lru Rust crate, which provides a ready-made LruCache type. Open cache_chatbot/src/solution/v5.rs to see how it is set up.
Crucially, note that the ChatbotV5 struct contains the Llama model (which you can use to create Chat objects, same as previous parts) and a cache field that holds the LRU cache. Your task is to implement chat_with_user and get_history.
Specifically, both of these implementations first try to find the relevant conversation in the cache (this code is already given to you). There are two cases:
- The conversation is found in the cache, which returns the underlying
Chatobject. You can use it directly to retrieve the history or add a new message. - The conversation is not in the cache. In this case, you will need to create a new
Chat, and read its content from a file (if one exists) or initialize it as an emptyChatif none exists.
Either way, this conversation now becomes the most recently used one, and you must therefore add it to the cache, including any new messages sent to or received from it.
Implement both get_history and chat_with_user.
Testing your code: ChatbotV5 is configured to keep no more than 2 conversations in the cache. You should test your code to ensure the following behavior is true:
- Open 2 tabs and log in as 2 different users, after the first login, they must both get inserted into the cache, and continuing to use them should not require reading from files after the first read.
- Open a 3rd tab and log in as a new user and begin chatting. The least recently used of the two earlier conversations should get removed from the cache, and the new conversation should replace it.
- If you log in or interact with a conversation that was removed from the cache, your code will read it from its corresponding file, and then put it back in the cache.
Hint: feel free to use print statements in your code to identify which cases (e.g., chat found or not found in cache) are being executed.
Hint: make sure you always write the new conversation session to the corresponding file, so that if the conversation ever gets evicted from the cache in the future, it will be stored / backed up in the file.
Experiment
Once you are happy with both V4 and V5, run the following command from the root of your repository:
cargo experiment
This experiment chats with your implementations of V3, V4, and V5 and measures how long it takes each to retrieve conversation history. It will print the timings for all three versions.
Identify which versions are slower and which are faster. Try to reason about why. Notice that V5 reports two timings: a hot and a cold result. Look at experiments/src/experiment.rs to understand what each measures, then explain the difference between them and how each compares to V3 and V4.
Submission Instructions
After you are done, make sure all your code is on a branch called complete_chatbot.
Please make sure that v4 and v5 behave as expected, that all tests pass (cargo test), and that cargo experiment runs successfully.
When you are done with Part 2, open a pull request from complete_chatbot to main. Your instructor will review it.
Also submit your repository via Gradescope.
Mini Project 3: Build your own Vec!
In this assignment, you will:
- Build two versions of vector, we will start with an easier but slower one, and then implement a more complex but much faster one.
- Get familiar with memory management including manual memory allocations and pointers.
Part 1: SlowVec
Your task in part 1 of the project is to complete the implementation of SlowVec (located in project_3_vec/slow_vec/src/lib.rs).
Our very first implementation of our own vector type.
This implementation will be a little slower, but it is easier to implement, so we will start with it.
You will implement a faster version in part 2.
Step 0 - GitHub Repository Setup
You should already have a fork of our GitHub repository from an earlier project. Synchronize your fork with our repository to receive the latest code, then pull main to your local machine. You should confirm that your fork contains project_3_vec.
Create a branch called vec off of main. You will do all of your work on this branch and submit it at the end.
Step 1 - Getting Started
Open the slow_vec folder using VSCode and navigate to slow_vec/src/main.rs.
main.rs
First, run the main function inside that file using VSCode or using the following command:
cd project_3_vec/slow_vec
cargo run --bin main
You will notice the program prints some output and then crashes with an error. This is because you have not completed the implementation of this Part 1 yet!
Let’s understand what this file contains.
fixed_sized_array(): The fixed_sized_array() function (line 9) demonstrates the FixedSizeArray type does and how it works.
FixedSizeArray is fully implemented for you, you do not have to change it. Although you are welcome to read its source
code (located under project_3_vec/fixed/src/lib.rs) if you are curious.
FixedSizeArray<i32> provides 4 important functions:
::allocate(n: usize): creates a newFixedSizedArraythat can store exactlynelements. It cannot store any more!.put(element: i32, i: usize): stores the givenelementat indexiin the array..get(i: usize) -> &i32: returns a reference to the element located at indexi..move_out(i: usize) -> i32: moves the element at indexiout of the array and return it.
get returns &i32 (the element stays in the array), while move_out returns i32 (the element is moved out and removed).
Lines 17–18 call get twice; line 21 calls move_out. Try uncommenting line 22 to call move_out twice. What happens? What if you call get after move_out?
Finally, slow_vec_push and slow_vec_remove test out .push and .remove
slow_vec_basics(): This function (line 33) demonstrates the SlowVec type:
- Line 35 creates a new variable of type
SlowVec<i32>. You will have to complete the implementation of this type in the following steps. For now, you just need to get a sense of what its API looks like. - Line 35 already puts 10, 20, and 30 in that
SlowVec. - Notice that you can print the content of
SlowVecusingprintln!. - Line 38 to 40 iterates of the
SlowVecand prints out its elements one at a time.
Behind the scenes, SlowVec is implemented using FixedSizeArray. But it’s implementation is missing two key functions push() and remove(), you will have to implement those in the next step.
slow_vec_push() and slow_vec_remove() demo pushing and removing elements from SlowVec.
They currently produce errors because you do not have push() and remove() implemented. When you do, go back and run these functions to make sure everything is correct!
lib.rs
After you are done running and tinkering with main.rs, let us look at project_3_vec/slow_vec/src/lib.rs.
Lines 11-13 define the SlowVec type using a struct! This is Rust’s way of defining custom types. Feel free to refer back to the Rust book for information about structs!
SlowVec<T> is generic over its element type. For example:
let slow_vec: SlowVec<bool> = SlowVec::from_vec(vec![true, false]);
println!("{slow_vec}");
let element = slow_vec.get(0); // element has type &boolThe SlowVec struct provides a bunch of methods (lines 16-70). Many of them are provided to you. You do not need to modify these functions and you can assume they are correct:
new(): creates a SlowVec that contains an emptyFixedSizeArrayof size 0.into_vec(...)andfrom_vec(...): transform betweenSlowVecand Rust’s built inVec. You do not need to use or understand these functions, we provide them mostly for testing and tinkering.len(...): returns the current length of theSlowVec.clear(...): clears all the elements in theSlowVec, resetting its contents to an emptyFixedSizeArray.get(...): retrieves a reference to the element at indexi. It does so by simply callinggeton the underlyingFixedSizeArray.
Step 2 - Implementation
Implement both the push function (line 62) and the remove function.
The trick to both functions is similar. The fixed field is of type FixedSizeArray, so we cannot change its size.
We cannot add more elements to it nor remove any elements from it.
Thus, we have to create a new FixedSizeArray with the new desired length, move over the elements from the old fixed to it,
as well as adding the new element (in the case of push) or skipping the removed element (in the case of remove) to it, and then
replace self.fixed with it.
So, the solution to both functions have a similar structure:
// Create a new FixedSizeArray of a different length
// If pushing, length should be old length + 1
// If removing, length should be old length - 1
// Look at the code in `lib.rs`, is there some function
// that can tell us what the old length is?
let tmp = FixedSizeArray::allocate(<<<<new length>>>>);
// loop over self.fixed and move over its elements to tmp
// either skip the one that should be removed (in case of remove)
// or add the new element to the end of tmp (in case of push)
...
// get rid of the old fixed field and replace it with tmp!
self.fixed = tmp;You can test out your implementation using slow_vec_push() and slow_vec_remove() in main.rs.
Step 3 - Testing and Experimenting
After finishing both solutions, run the tests:
cargo test -- --test-threads=1
If you pass all the tests, then your solutions are correct and you will get full credit. If you fail some tests, go to the corresponding
file under tests/, read the failing test, and try to find out what went wrong so you can fix it.
Also look at the content of src/memory.rs and then run it using this command:
cargo run --bin memory
This program confirms that SlowVec does not mismanaged memory, e.g. by losing track of data or forgetting to remove elements in memory.
You have not used any features that corrupts memory. So this is actually guaranteed by Rust.
However, in part 2, you will use some unsafe Rust features that may corrupt memory. These features allows us to implement
a faster vector. However, they are dangerous, and if you make mistakes in that implementation, your vector may lose elements or
forget to clean them up. memory.rs will come back and help you find and fix such errors in step 2.
Part 2: FastVec
Your task in part 2 of the project is to complete the implementation of FastVec (located in project_3_vec/fast_vec/src/lib.rs).
This implementation will be much faster than part 1, but it will be more complicated to implement.
Step 0 - Background
Before you get to coding, you need to understand our strategy for how to make FastVec be (significantly) faster than SlowVec. This strategy relies on two parts:
- Doubling the size of the vector when pushing to a full vector.
- Manually managing memory (instead of relying on
FixedSizeArray).
Doubling Vector Size on Resize.
The main idea behind push with SlowVec is to create a new FixedSizeArray, whose length is one plus the old length, then moves over
all the previous elements to the new, bigger array. This makes it so push always takes O(n) steps, where n is the current length of your vector.
However, with Rust’s builtin Vec (and equivalent in other languages, such as a list in Python), push is O(1) (on average). How come?
These faster implementations distinguish two notions:
- The length of the vector: the number of elements currently in the vector,
- The capacity of the vector: how many elements the vector can have at most before it needs to be resized.
In SlowVec, these two were the same, thus, for every push, the SlowVec needed to be resized. In FastVec, you will notice that the struct contains len and capacity fields.
In fact, if you create a new FastVec using FastVec::new(), you will notice it starts with capacity 1 (and len 0, because it is empty). This allows you to push one element “for free”,
as the FastVec already has space for it.
The key idea is that when the capacity equals the len, the vector is full, and any future push will need to make it bigger so that it can add a new element to it.
In that case, we double the capacity (i.e., the size), rather than just increasing it by 1 (as in SlowVec).
For example, consider starting with a fresh new FastVec, and then issuing 8 pushes to it:
FastVec::newreturns an empty vector with capacity 1: len = 0, capacity = 1- First push: the vector has enough capacity to simply put the element in, without resizing. This push is
free, i.e., takes one step. len = 1, capacity = 1. - Second push: len equals capacity, the vector is full, we resize it so that capacity = 2*1 = 2, and move all previous elements to the new resized vector (similar to
SlowVec), then add the new element at the end. This takes two steps (one to move the previous element, one to add the new element). len = 2, capacity = 2. - Third push: len equals capacity, the vector is full, we resize it so that capacity = 2*2 = 4, and move all previous elements. This takes three steps. len = 3, capacity = 4.
- Fourth push: len < capacity, we simply add the new element at the end. This takes one step. len = 4, capacity = 4.
- Fifth push: len equals capacity, vector is full, resize it to capacity = 4*2 = 8. This takes 5 steps. len = 5, capacity = 8.
- Sixth, seventh, and eight pushes: len < capacity for each of these pushes, so they each take only one step, after all of them, len = 8 and capacity = 8.
Using this strategy, we pushed 8 elements, and it took 1+2+3+1+5+1+1+1 = 15 steps in total. Which averages out to less than 2 steps per element. In fact, if we use this strategy to push infinitely many elements, the average converges to 1 step per element.
If you want a more visual demonstration of what this looks like, take a look at this helpful video.
Manually Managing Memory
We will not use FixedSizeArray in this part, and instead we will directly manage the underlying memory using pointers.
This is more complex to implement (and can be dangerous if not implemented correctly as it can result in various memory corruptions and problems!).
However, it gives you way more control about when and how to allocate memory, including allocating memory without using it directly, but rather, saving some of it free for the future.
Using the provided memory allocator library (MALLOC)
To help you with memory management, we provide a memory allocator library as part of the stencil. lib.rs already uses it:
use malloc::MALLOC;The library provides you with two important functions that you will need to use:
// Allocate new memory with the given size (in bytes).
// Returns a pointer to this newly allocated memory.
unsafe fn malloc(bytes: usize) -> *mut u8
// Free a previously allocated region of memory
// You must pass a pointer than was returned by malloc
// and free will free the corresponding memory (all of it).
// free remembers how many bytes that allocation was, and will
// automatically free all these bytes.
unsafe fn free(ptr: *mut u8)Here is an example:
// Allocate four bytes
let ptr1: *mut u8 = unsafe { MALLOC.malloc(4) };
// We can now do things with these four bytes
// When we are done, we should free them.
unsafe { MALLOC.free(ptr1) };Look closely at the type of ptr1, it is *mut u8. u8 represents a single byte in Rust. So, *mut u8 is a mutable pointer to byte(s).
But what if we want to deal with other types that are not one byte, for example, an i32? Fortunately, everything boils down to bytes on a computer, because
everything is simply zeros and ones. We just need to make sure we have allocated the correct size for that type.
An i32 is 4 bytes in size, so the above exam allocates enough memory for exactly one i32. However, it is not a good idea to try to memorize the sizes of different types.
Furthermore, we may not even know what the type is (e.g., FastVec like SlowVec is generic over any type the user of the vector chooses, denoted by T). Fortunately,
Rust has a helpful function we can use that tells us the size of a type.
let size_of_i32 = size_of::<i32>();
let size_of_t = size_of::<T>();Now, we can allocate pointers to these other, more helpful types! We have to use the correct size (in bytes) and then cast the resulting pointer
to our desired type using the as keyword:
let ptr1: *mut i32 = unsafe { MALLOC.malloc(size_of_i32) as *mut i32 };
let ptr2: *mut T = unsafe { MALLOC.malloc(size_of_t) as *mut T };Now, what if we want to allocate memory for more than one element? It’s all bytes: we just need to make sure that we have enough of them.
// ptr3 can hold up to 10 elements of type i32s.
let ptr3: *mut i32 = unsafe { MALLOC.malloc(size_of_i32 * 10) as *mut i32 };
// ptr4 can hold up to n elements of type T.
let ptr4: *mut T = unsafe { MALLOC.malloc(size_of_t * n) as *mut T };Using the pointers after they are allocated
Now, we know how to allocate and free pointers. But how do we use them?
There are three ways to use a pointer:
- Writing to a pointer with
ptr::write(): this overwrites the data at the pointer with the given data. It will not free or destruct the old data, it will simply overwrite it. - Moving data out of a pointer with
ptr::read(): this will move out the data pointed to by the pointer and destroy/free that data. - Getting a reference to data pointer to by a pointer:
&*[name of your ptr]: this returns a reference to the data, it does not move out nor destroy it.
The difference: &* borrows the data (the pointer remains valid, you can read again), while ptr::read moves it out (the slot is empty until written again).
Importantly, to use these operations correctly, you need to make sure these conditions are upheld:
- Never use
ptr::reador&*on a pointer before writing withptr::write()to that pointer (since there is no data yet). - Never use
ptr::reador&*on a pointer afterptr::read()(since the data is moved out), until you write to it again. - If a pointer has data, you must first use
ptr::read()to move it out, before usingptr::write()to write new data to it.
Rust cannot help you ensure that these conditions are met. Instead, you must do so yourself by thinking hard about your code. In fact, all of these operations are unsafe. These are special Rust operations that Rust allows us to execute to give us flexibility, but Rust cannot guarantee that they will not create problems (the technical term is undefined behavior). Instead, we must ensure that they will not create problems by carefully thinking about the code and ensuring it is correct.
To use these features, we must explicitly use the unsafe keyword, to tell Rust that we know what we are doing. If we do not use unsafe, the Rust compiler will give an error about these operations.
let my_pointer: *mut i32 = unsafe { MALLOC.malloc(size_of::<i32>()) as *mut i32 };
// This tells Rust we know what we are doing and we want to use unsafe
// operations.
unsafe {
// First write.
ptr::write(my_pointer, 5); // Now, my_pointer points to 5.
// Let us say we want to overide the data with 10.
// We should first move the previous value out!
// Then write to it.
let _old_data = ptr::read(my_pointer);
ptr::write(my_pointer, 10);
let v: &i32 = &*my_pointer;
println!("{v}"); // will print 10
let v2: i32 = ptr::read(my_pointer); // the data has been moved out of my_pointer
// You should not try to read data from my_pointer again
// (although it might still work with i32, but with more complicated types, it will not!)
println!("{v2}"); // will print 10
}What about when the pointer points to many elements? We can use add() to select which element we want to look at.
let my_pointer_2: *mut i32 = unsafe { MALLOC.malloc(size_of::<i32>() * 10) as *mut i32 };
unsafe {
// This points to element at index 2, i.e. the third element.
let ptr_2: *mut i32 = my_pointer_2.add(2);
ptr::write(ptr2, 33);
let this_is_33: i32 = ptr::read(ptr2);
// This points to the element at index 9, i.e., the last element.
let ptr_9: *mut i32 = my_pointer_2.add(9);
ptr::write(ptr_9, 99);
println!("{}", &*ptr_9);
// add() is unsafe because if you misuse it, you might create problem,
// what do you think will happen with this code?
let ptr_10: *mut i32 = my_pointer_2.add(10);
println1("{}", &*ptr_10);
}main.rs and memory.rs
Just like in part 1, we provide fast_vec/src/main.rs and fast_vec/src/memory.rs to serve as a playground for you to
experiment with MALLOC and with dealing with pointers. First, navigate to the fast_vec folder:
cd project_3_vec/fast_vec
Then you can run them using these commands:
cargo run --bin main
cargo run --bin memory
Take a look at main.rs, and specifically, the malloc_and_ptr() function. Run it and try to understand what it outputs.
Feel free to modify it or add more code to it to experiment with other cases.
When you are confident that you understand the basics of MALLOC and pointers, move on to the next step.
Step 1 - Implement get
Implement get on your vec branch.
Start by assuming that the vector already has enough elements pushed to it. How would you use the pointer operations described in the background above
to retrieve the element at index i from self.ptr_to_data?
Hint: You only want to get the data, you do not want to move out or destroy it. Users of your vector should be able to get the data again in the future
if they want to. Consider using &*.
Hint: You will need to use unsafe and you will need to use self.ptr_to_data.add([your index]).
You can try out your implementation using main.rs to see if it works.
After you make the basic version work, consider what would happen if the callers provided a bad index. E.g., if i is greater than or equal to self.len.
Rather than returning random/garbage data or causing memory issues, it is best you create an error to inform users that they are using get wrong
and providing a bad index.
Consider adding this code below to the top of your function implementation.
if i >= self.len {
panic!("FastVec: get out of bounds");
}After you are done, run the following test, and if it passes, move on to the next part.
cargo test get_strings -- --test-threads=1
Step 2 - Implement push and remove.
Implement remove and push on your vec branch.
Implement remove. Unlike in part 1, you do not need to resize the vector, since FastVec can support having a capacity different than its length.
Instead, you can simply remove the element at the given index, and then move every element after it one step backwards. For example, assume you had a vector with [1, 3, 5, EMPTY] and remove(1) is called, you can implement your code such that the vector becomes [1, 5, EMPTY, EMPTY] without having to allocate new memory or resize the vector.
Consider what should happen if callers provide an index that is outside the length of the vector. Similar to get, you should panic in this case using this error message:
panic!("FastVec: remove out of bounds");Hint: Remember to first move out the element to be removed using ptr::read.
Hint: For every index j greater than the index you want to remove, you should read the element at index j using ptr::read, then write it to index j-1 using ptr::write.
Implement push. You should use the size doubling strategy we described above in the background.
Hint: Use MALLOC.malloc to allocate new memory of twice the size.
Hint: Move over all the elements from the previous pointer to the new pointer using ptr::read and ptr::write
Hint: Do not forget to write the new element using ptr::write and to update self.ptr_to_data, self.len, and self.capacity.
Run the tests using
cargo test -- --test-threads=1
If your implementation of both push and remove is correct, all the tests should pass except one test called clear_tracker (leave that one for the last steps).
If other tests fail, look at their code (you can find it under tests/, or by using grep -R "[name of test]").
Step 3 - Fix bug in clear
You will notice that the clear_tracker test fails even when you implement both push and remove correctly.
This is because we have intentionally left a bug in the clear function we provided.
You need to fix this bug.
Look at the output of running memory.rs. You will notice that some data is not free-ed even after calling clear(). You need to make sure that data is free-ed.
Hint: remember the rules of using pointers above. How can you destroy the data the pointer is pointing to?
Hint: remember ptr::read()?
Step 4 - Run the provided experiment
Use the following command to run the provided experiment:
cargo run --bin experiment --release
This will produce a plot under plot.png in the fast_vec folder. Look at the plot. In this plot, the x-axis represents the size of the vector, and the y-axis represents the time needed to push one element to the vector with that size. For FastVec, the time is reported in microseconds, for SlowVec the time is in hundreds of microseconds.
Make sure you understand what you are seeing. E.g., which of the two implementations is faster, and what trends you see as vector sizes grow.
Step 5 - Submission
Make sure all of your code is in the vec branch and that you have pushed it to your fork on GitHub.
Please make sure your code compiles and passes all the tests and that you are able to run the experiment successfully.
When you are done, open a pull request from vec to main. Your instructor will review it.
Also submit your repository via Gradescope.